Today's Big Data Pulse

Data‑Engineering Bottlenecks Shift From Legacy Tech to Leadership Gaps
Three 2026 surveys of 1,629 data professionals show that weak leadership direction and poor requirements now account for 40% of top‑bottleneck votes, outpacing legacy systems at 25%. By April, 50% of respondents cite lack of clear ownership as the biggest pain point, while better tooling is mentioned by under 5%.
Also developing:
By the numbers: Ampere Analysis acquires PlumResearch

Designing SQL Server Pipelines That Are Ready for AI Before You Actually Need AI
The article argues that AI readiness starts with robust SQL Server schema design, not with machine‑learning models. It highlights that stable, non‑recycled primary keys, preserved historical records, and clear audit columns are essential for future feature engineering. By separating raw events from derived attributes and avoiding overloaded or free‑text‑only columns, organizations keep data flexible for analytics. The piece provides a practical checklist to assess whether a database can support downstream AI pipelines without costly retrofits.

Radim Marek: PostgreSQL Statistics: Why Queries Run Slow
PostgreSQL’s query planner relies on catalog statistics from pg_class and pg_statistic to estimate costs. When these statistics become stale—due to bulk loads, schema changes, or insufficient vacuum—the planner can choose inefficient plans, turning milliseconds queries into minutes. The article explains...

Modern Cloud Analytics in 2026: Architecture, Use Cases, and Pitfalls – Shopify
Shopify’s 2026 guide outlines what makes cloud analytics truly modern, emphasizing a cloud‑native stack that couples elastic compute with a semantic layer, governed self‑serve, and built‑in FinOps. It contrasts legacy on‑prem and “cloud‑washed” BI with a fully modular architecture that...

The Hidden Cost of Custom Logic: A Performance Showdown in Apache Spark
A recent benchmark shows that standard Python UDFs in PySpark dramatically slow pipelines because each row must be serialized to a Python worker. Using Pandas (vectorized) UDFs cuts execution time by roughly fourfold by leveraging Apache Arrow’s columnar transfer. Native...

Query CSVs Directly with DuckDB—No Load, Faster
Instead of loading CSVs into pandas just to run one query, you can use DuckDB to run SQL directly on files. No loading. No waiting. Just query the file and get results. It’s also 20x faster and uses way less memory. Here’s how...

5 Useful Python Scripts for Automated Data Quality Checks
The article presents five open‑source Python scripts that automate common data‑quality checks, ranging from missing‑value analysis to cross‑field consistency validation. Each tool reads CSV, Excel or JSON inputs, applies schema‑driven rules or statistical methods, and generates detailed reports with actionable...

700MW Data Center Could Be Built at Port of Dunkirk, Northern France
The Dunkirk Port Authority has opened a 21‑hectare brownfield site for a potential AI‑focused data center, offering developers a power connection ranging from 400 MW to 700 MW. Power will be supplied by RTE from the nearby Flanders Maritimes substation, with a...

Upcoming Research On Digital Twins For Data Centers
An upcoming research initiative will evaluate digital‑twin technology for data centers, aiming to identify high‑ROI use cases that surpass basic spreadsheet analysis. The study will assess available solutions, pinpoint scenarios—such as infrastructure vendor selection—that deliver quick, measurable value, and define...

🎥 MSCI's Luke Flemmer - "Bringing Clarity to Investment Decisions"
In this episode, Luke Flemmer, head of private assets at MSCI, explains how standardizing and normalizing data can unlock transparency, price formation, and liquidity in private markets, drawing parallels to past evolutions in bonds, FX, and equities. He argues that...
Bindplane Launches Integrations for VictoriaMetrics to Make It Even Easier to Collect, Process, and Route Opentelemetry
Bindplane announced native destinations for the VictoriaMetrics ecosystem, allowing users to route OpenTelemetry metrics, traces, and logs directly to VictoriaMetrics, VictoriaTraces, and VictoriaLogs. The integration provides vendor‑neutral, OpenTelemetry‑native pipelines that eliminate manual exporter configuration and mitigate collector drift. It also...

Confluent Intelligence Adds Streaming Agents Into the Mix to Enable Agent-to-Agent Collaboration
Confluent Intelligence has introduced Streaming Agents, built on Google’s Agent2Agent protocol, to enable AI agents to share real‑time context and collaborate across platforms. The preview feature connects data sources such as BigQuery, Databricks, Snowflake and LangChain to third‑party systems like...

Timescale Beats Clickhouse‑Postgres Combo for Simplicity
Clickhouse is trying to push postgres + clickhouse as the ultimate analytics DB stack. But tbh adding an eventually consistent database to your stack that you needed to sync too is anything but trivial. Love the product but I'd just use...

Tomas Vondra: The Real Cost of Random I/O
Tomas Vondra revisits PostgreSQL's long‑standing default of random_page_cost = 4.0, showing that modern SSDs make random I/O far more expensive than the parameter suggests. By timing sequential and index scans on a 4.4 GB table, he derives a random_page_cost of roughly 25‑35 on...

Snowflake Posts 30% Revenue Surge, Record Bookings
Snowflake prints 30% revenue growth and record bookings momentum $SNOW delivered Q4 revenue of $1.28B (+30% YoY) with product revenue at $1.23B (+30%) and EPS of $0.32, beating estimates by 23%. Growth is re-accelerating at scale. RPO climbed to $9.77B (+42%), billings...

Banks – and Google – Open to Gemini-Powered Exfil via Public API Keys, Researchers Say
Security firm Truffle Security revealed that publicly exposed Google API keys can be upgraded to full‑access Gemini credentials, enabling data exfiltration from any organization using them. A November scan uncovered 2,863 such keys, affecting major banks, security vendors, and even...

AI Proof of Concept Development Cost & How to Build a Successful AI POC (2026 Guide)
An AI proof of concept (POC) is a focused, short‑term project that validates technical feasibility and business value before full‑scale investment. Costs vary widely, driven primarily by data readiness, problem complexity, integration needs, and infrastructure choices, with data preparation often...

Treat Data as Assets, Not Just Jobs.
Data Product: why do we need this data? Data Asset: what is this data and how do we maintain it? I've found the most practical definition of data products comes from Dagster's software-defined assets. Each asset has a clear definition, dependencies, and...

AI Boom Fuels Data Demand for Small Innovators
SONAR is having the best quarter in years. One of my board members asked if I were concerned about the rise of AI and if it would be a drain our data business. I told her that we are seeing...

How to Build an Elastic Vector Database with Consistent Hashing, Sharding, and Live Ring Visualization for RAG Systems
The tutorial walks through building an elastic vector‑database simulator that uses consistent hashing with virtual nodes to shard embeddings across distributed storage. It includes a live, interactive ring visualization that shows how adding or removing nodes only reshuffles a tiny...
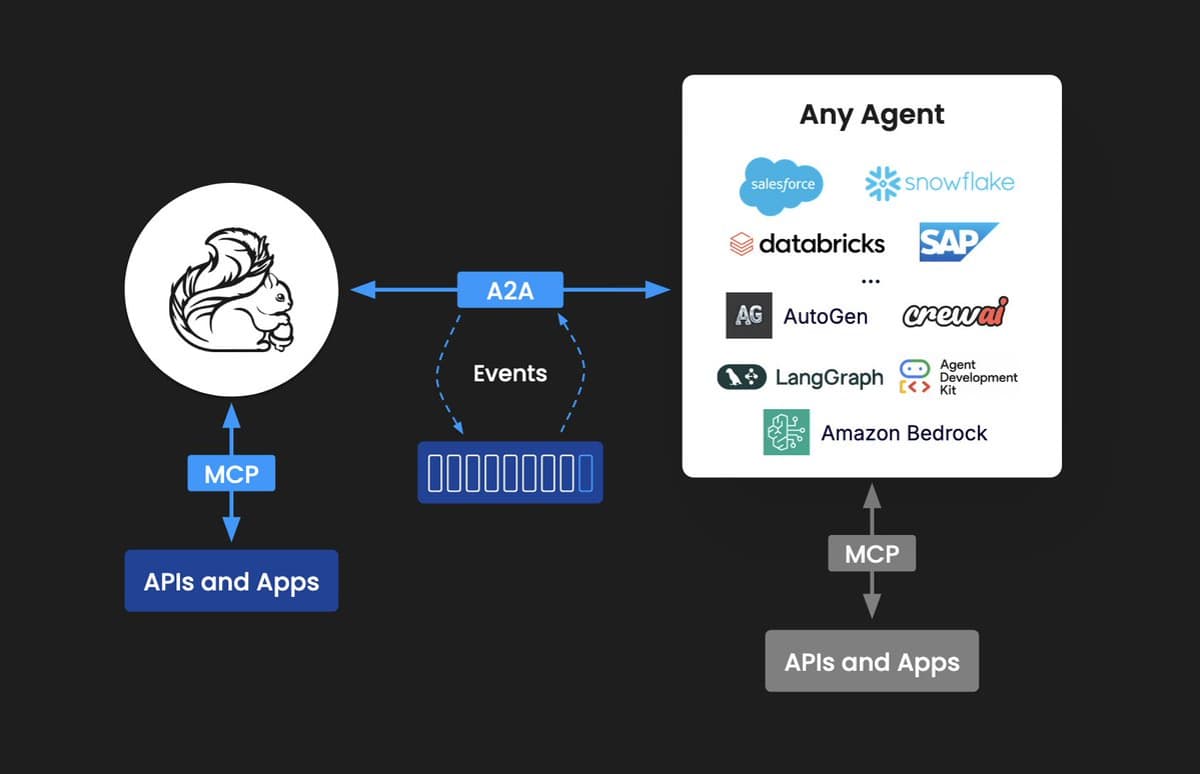
Confluent Adds MCP and A2A Support to Its Platform
Agent standards like MCP and A2A are starting to show up in more types of packaged software. @confluentinc just shipped updates to their data products, including their "intelligence" platform that now supports A2A and MCP integrations. https://t.co/n8teMonFMW https://t.co/1f7afnSw8K

Data Skills, Not AI, Drive Future Business Success
73% of companies are investing more in data and analytics skills right now. Not AI skills. Data skills. Your AI returns depend entirely on your data foundation. The benchmark comparison doesn't change that.

Vast Data Integrates AI OS Into Nvidia GPU-Powered Servers
Vast Data and Nvidia have launched the CNode‑X, a GPU‑powered server that embeds the Vast Data AI Operating System directly onto Nvidia hardware. The integrated solution is optimized for AI pipelines, high‑performance analytics, vector search, retrieval‑augmented generation and agentic workloads....
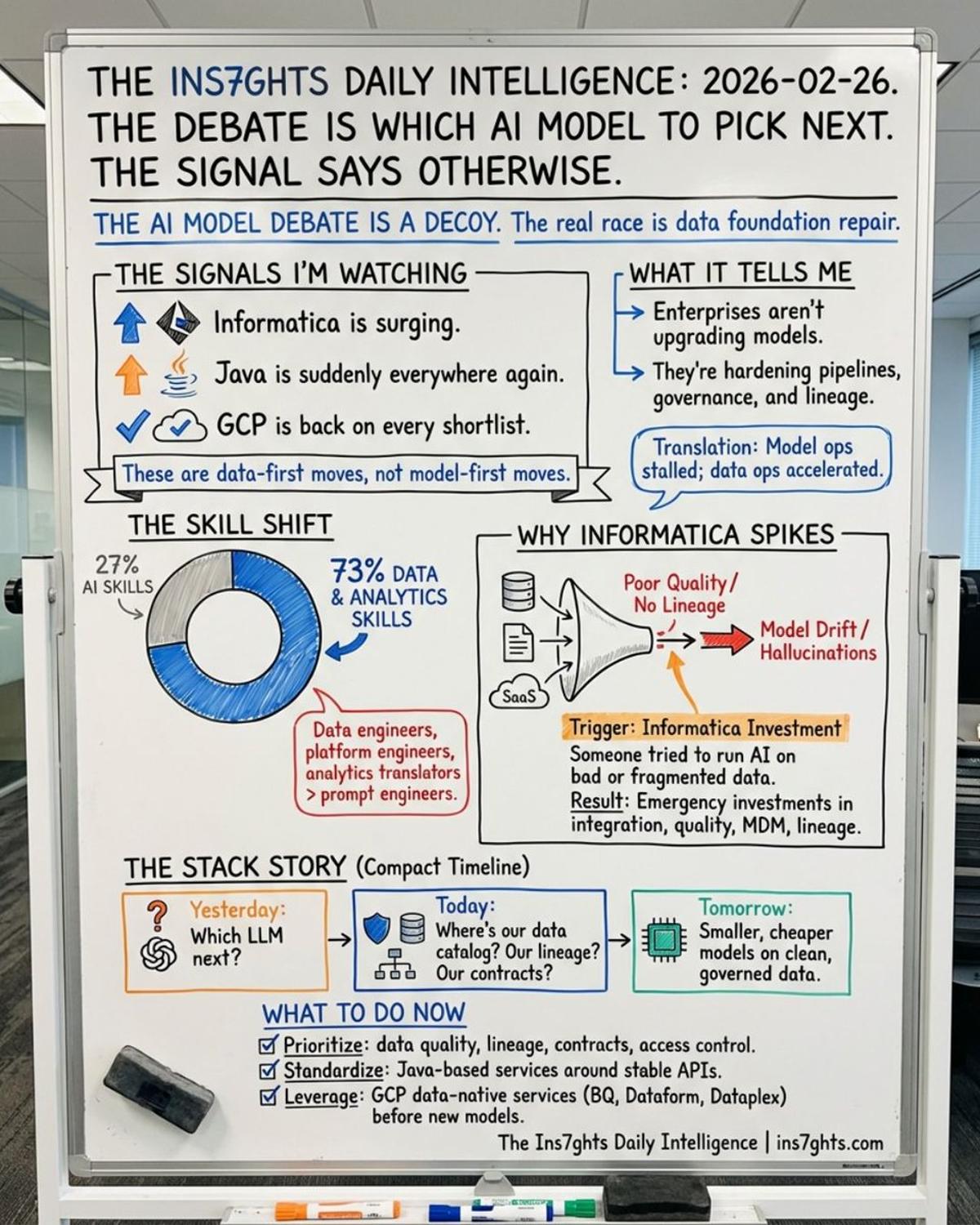
Data Skills Trump AI Hype in Modern Strategies
The debate: which AI model to bet on. What I'm watching instead: Informatica surging. Java everywhere. GCP back on the shortlist. 73% of companies investing more in data skills. Not AI skills. Your AI strategy is only as strong as the data layer...

Real‑time Data Powers HCF’s Analytics Transformation
Recently I caught up with Amiet Dhagat, Head of Data Services Analytics and AI for HCF, to get the inside story around their stellar success in transition from static data to dynamic data, and why real-time data has been so...

DHS Wants More than Biometrics in US-EU Data Sharing Agreement
The United States and the European Union are negotiating the Enhanced Border Security Partnership (EBSP), which would grant visa‑free travel to EU citizens in exchange for access to European biometric databases. The latest draft does not explicitly prohibit the use...

Open‑Data Slack Clone Will Trigger Mass Migration
Slack will be the Waterloo of open vs closed data. Someone is going to make a slack clone where you get unfettered access to your own data, and people really will switch en masse.

Managed Iceberg Lets Providers Own the Metadata Control Plane
Why are hyperscalers racing to offer managed Iceberg? Because whoever controls the catalog controls the ecosystem. If your tables are in a managed Iceberg service, you can query them from any engine - Spark, Trino, DuckDB, whatever. But your metadata stays with...

Percona Operator for MongoDB 1.22.0: Automatic Storage Resizing, Vault Integration, Service Mesh Support, and More!
Percona released Operator for MongoDB version 1.22.0, adding automatic Persistent Volume Claim resizing, HashiCorp Vault integration for system user credentials, and native service‑mesh compatibility via the appProtocol field. The update also expands backup and restore capabilities, including replica‑set name remapping,...
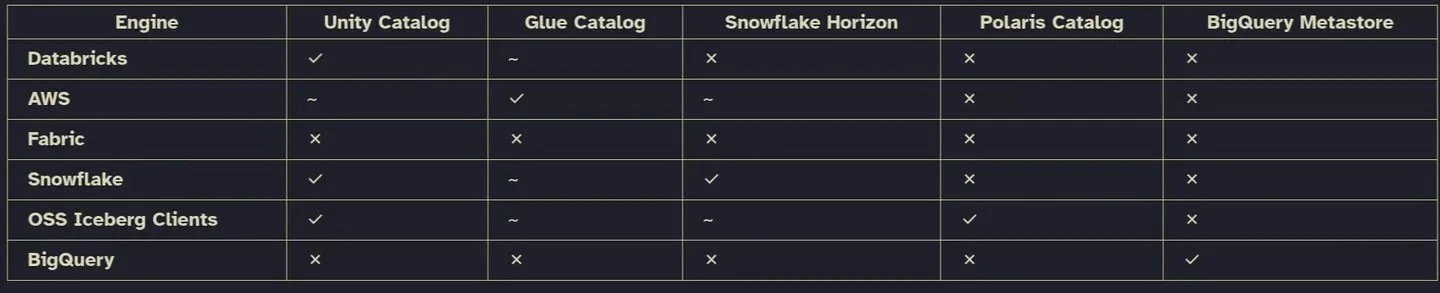
Choosing Optional Catalogs for Open Table Formats
Are we still using table catalogs for open table formats? Haven't heard too much lately. I like OTFs, but making it non-optional to have a catalog isn't great. That's why I like prefer the option to use one without. But if you...

Privacy Must Be Built Into AI Data Workflows
RT High-level policies aren't enough. It's time for audits, training, DSPM, and privacy-by-design in AI workflows. If privacy isn't built into how data moves, you're hoping - not leading. #DataGovernance #AI #CIO @Star_CIO https://t.co/Naq82FuMWZ
Joule with SAP Signavio Solutions Is Now Generally Available
SAP announced that Joule, its generative‑AI platform, is now generally available integrated with SAP Signavio. The solution adds a natural‑language conversational layer to process models, allowing users to query owners, flow descriptions, and regional variations instantly. Joule orchestrates workflows across...

Separate Storage and Compute Redefines Modern Databases
Why we're excited about Lakebase GA: most database services are based on outdated assumptions leading to poor operability, scalability and devex.
Data Governance: The Crucial Anchor Amid Conflicting Sources
Every data conversation I tracked this week led back to the same concept. Data Governance. Not as compliance. As the center of gravity. 47 data sources. 6 different owners. 3 definitions of "customer." Your AI agent has no idea who to believe. https://t.co/ZrW6iptSqs

Spark, Lakehouse & AI: A Deep Conversation with Bart Konieczny
In a recent Data Engineering Central podcast, Bart Konieczny discussed the evolving synergy between Apache Spark, lakehouse architectures, and artificial intelligence. He highlighted Spark's latest performance enhancements, including Catalyst optimizer refinements and native GPU acceleration. Konieczny explained how lakehouses bridge...

Enterprise Data Stack Becomes AI Delivery Engine
Everyone’s watching which LLM wins benchmarks. I’m watching Informatica suddenly show up everywhere. GCP coverage up 200%. The enterprise data stack isn’t being replaced by AI. It’s becoming the delivery mechanism for AI. The boring infrastructure is now the moat. https://t.co/9dxQv330NZ
Kore Enhances Integrate with Features that Manage and Transform Data
KoreTech unveiled a suite of updates to its Kore Integrate platform, adding new connectors for Canals.ai, Blue Yonder WMS, LeadSmart CRM, FieldPulse and Housecall Pro. The release also upgrades security protocols and promises support for Microsoft SQL Server 2025. Kore Integrate already...
Entrinsik to Showcase Informer at Several Conferences Spring 2026
Entrinsik announced a spring 2026 roadshow, speaking and exhibiting at Accelerate, Ellucian Live, and MultiValue World. Scott Allen will lead a session on data‑driven agency growth at Accelerate, while the company will demo Informer AI Assistants for campus‑wide personalization at...

Scality RING Becomes Back-End Object Store for WEKA NeuralMesh
Scality and WEKA announced that Scality RING will serve as the back‑end object store for WEKA’s NeuralMesh high‑performance AI file system. The partnership leverages NeuralMesh’s SSD‑based front‑end with RING’s cost‑efficient, disk‑based object tier, delivering up to ten times faster performance than...

Data Execution Gap Persists Despite Better BI Tools
70% of executives say they have difficulty acting on data. Meanwhile, Power BI just won the 2025 Gartner Magic Quadrant. Again. The tools keep getting better. The problem isn’t the tools. It never was. Source: https://t.co/KNtNLIRTOQ https://t.co/ZOAPhWZKSf

A Data-Driven Approach to Subscriber Satisfaction
Newsday, a Long Island‑based multiplatform news outlet, has leveraged the American Press Institute’s Metrics for News (MFN) analytics tool since 2018 to turn data into subscriber growth. By tracking audience enthusiasm for niche beats, the paper launched new content initiatives,...

Zifo and Maze Therapeutics Partner to Power Precision Medicine
Zifo and Maze Therapeutics have teamed up to launch an AI‑powered platform that manages, stores, and scales massive biobank datasets. The solution tackles the fragmentation of genetic, proteomic, and phenotypic data by providing a unified workflow that delivers summary statistics...

Muhammad Aqeel: Semantic Caching in PostgreSQL: A Hands-On Guide to Pg_semantic_cache
The article introduces pg_semantic_cache, a PostgreSQL extension that stores query results alongside vector embeddings to enable semantic caching. By matching on meaning rather than exact text, the extension can identify duplicate intents across varied phrasing, dramatically increasing cache hit rates....

Snowflake Postgres: Unify Postgres and Analytics on One Platform
Snowflake announced the general availability of Snowflake Postgres, a fully managed PostgreSQL service built directly into the Snowflake platform. The offering delivers 100% community‑Postgres compatibility while leveraging Snowflake’s security, high‑availability architecture, and native AI capabilities. By unifying transactional and analytical...
2028 - THE GREAT DATA RECKONING
The memo from Reis Megacorp outlines a 2028 scenario where AI agents can design, test, and deploy end‑to‑end data pipelines, rendering many data‑tooling jobs obsolete. By mid‑2027 the data labor market split: elite engineers commanding $400K+ salaries, a middle tier...
Collate Introduces Semantic Intelligence Graph to Make Enterprise Data Understandable to AI
Collate, a semantic intelligence firm, unveiled a new Semantic Intelligence Graph that converts enterprise metadata into a machine‑readable RDF‑based graph. The launch includes AI Studio, offering four pre‑built agents—Data Quality, Tier Management, Documentation, and SQL Query—to automate data tasks. An...

Building Event-Driven Data Pipelines in GCP
Google Cloud Platform enables event‑driven pipelines that replace idle batch jobs with immediate reactions to data changes. The reference architecture uses Firestore as the event source, Cloud Functions or Eventarc to capture changes, Pub/Sub as the messaging backbone, and Dataflow...

Exploring Emerging Git‑Style Tools for Data Management
Git for data is still underexplored, and it is an area that is changing so fast. That's why we look at actual tools/features that showcase how to apply a Git-like workflow for data. I compared Git-like tools for data I could...

One-Line Code Swap Moves Cassandra to Spanner, Auto-Embeds in BigQuery
Simple is good. One-line code change to switch from Apache Cassandra to a @googlecloud Spanner database. https://t.co/2n6AJutoNM Generate embeddings automatically for @googlecloud BigQuery table. https://t.co/SqIQzawOvt https://t.co/zWknasRT6r

How Disconnected Clouds Improve AI Data Governance
Microsoft has launched Azure Local, a fully disconnected private cloud that unifies Azure, Microsoft 365, and Foundry services for regulated enterprises. The offering supports offline governance, policy enforcement, and AI inferencing on on‑prem hardware, ensuring data never leaves customer‑controlled boundaries....

5 Python Data Validation Libraries You Should Be Using
Data validation is gaining prominence as pipelines become more complex, and Python now offers a diverse set of libraries to address this need. The article reviews five tools—Pydantic, Cerberus, Marshmallow, Pandera, and Great Expectations—each targeting a different validation paradigm, from...