
Clean Data Foundations Drive Smarter AI Decisions
Bad data in, bad decisions out – no matter how sophisticated the AI. Here's what fixing the foundation for business intelligence actually looks like. https://t.co/IYNpBESVGW #DataIntegration #BusinessIntelligence https://t.co/ZSDrFbc5tq

From Intelligence to Action: Rethinking the Data Stack
.@Google’s take: the modern data stack isn’t failing—it’s misaligned. Built for humans answering questions. Agents need systems that execute decisions—continuously, autonomously, at scale. The shift: from systems of intelligence → systems of action. That’s the real bet behind Agentic Data...

Jay Kreps Traces Kafka’s Birth and Confluent Foundations
During @IBM Think day 1, keynote 3, @confluentinc and @apachekafka co-founder Jay Kreps explains how Kafka came about and how it became basis of Confluent. #Kafka #IBMThink #Think #Think2026 @robdthomas @ArvindKrishna @furrier @dvellante @dhinchcliffe @holgermu https://t.co/cb9TDjuQG2

SAP Expands Data Platform with Dremio, Prior Labs Acquisitions
.@SAP acquires @Dremio, @PriorLabs as it builds out its data platform plan https://t.co/78ISBnRjAP SAP said it will acquire Dremio, an open data lakehouse player, in a move that aims to use SAP Business Data Cloud combine SAP data with non-SAP...

SAP Bolsters AI Data Layer with Dremio, Prior Labs
@SAP to acquire @dremio and @prior_labs ... the data landscape for SAP AI is quickly evolving. My Take: 3 Positives + Good to see SAP working on the data foundation that powers Agentic AI. + Tabular data is essential for enterprise...

Unstructured Data Security Hindered by Visibility Gaps
RT One of the biggest security challenges with unstructured data is the lack of visibility and lineage as information moves across systems, clouds, and teams." #DataLineage #AI @Star_CIO https://t.co/PYomJYHDkY

Context, Not Models, Drives Generative BI Success
Generative BI doesn’t fail because of models. It fails because of missing context. OpenBI solves that. → one standard → any platform → governed outputs From answers to certified BI assets. That’s the real shift ⚡ 📌 Part 4/4 on Generative BI https://t.co/rzlsMalE4X 🚀 Meet Databreeze at AI Week Milano (May...

Synthetic Data Enables Safe Workforce Evolution Simulations
Use Synthetic #Data to Simulate Workforce Evolution Without Exposing Employee Data by @antgrasso #DataScience #BigData https://t.co/p4BdPIKlSB

Agents Disrupt Database Contracts; Build Defensive Data Layers
Have agents broken the unspoken contract we had with our databases? You know, human-authored apps running deterministic code and predictable queries? @arpit_bhayani wrote a terrific post for how to create a defensively designed data layer ... https://t.co/8OOXrmkD6g

Centralize Metrics with a DRY Analytics API
Instead of duplicating measures in each BI tool, store them centrally in an Analytics API. This is the DRY principle applied to metrics. One metric definition, accessible via GraphQL, SQL, or REST. https://www.ssp.sh/brain/analytics-api

Data Migration Remains Underestimated Despite Persistent Industry Challenges
Data Migration Is Still Hard: Why the Industry Keeps Underestimating It "Every few years the IT industry rediscovers something that experienced practitioners already know: moving data is difficult." https://t.co/Qy0esoSAIR

Turning Data Chaos Into Business‑Driving AI on Google Cloud
From Data Chaos to Confident AI: How Overdose Built a Semantic Foundation on Google Cloud https://t.co/MEyCiKRO4Q Overdose CEO Paul Pritchard unpacked exactly what it takes to get from scattered #data sources to #AI that actually moves the business forward.

Boomi Shifts to Data Activation, Tackles AI Semantic Gap
I haven't written about @boomi in a while. That changed when I noticed they stopped calling themselves an integration company sometime in Q1 2026. The new label is "data activation company" and it's not cosmetic. Integration Platform as a Service...

Grant Is the Proper Term for Permission on Entities
Randomly remembered the time when Grant Henke worked on AuthZ for Apache Kafka and tried to come up with a term for "giving a user permission to perform action on an entity". Grant, it is called "grant". As in: "GRANT...

83% Predict AI Demand Will Outpace Data Infrastructure Soon
At least 83% of the 1,125 tech managers surveyed by Cockroach Labs agree that AI demand will exceed the capacity of most data infrastructure in the next 12–18 months. (My write-up in DBTA) https://t.co/H9Zchu6dgC

Replace Patterns in a Single Column Using Command‑line Tools
1/Need to replace a pattern, but only in column 5? Don't touch the rest of the file. Don't reach for Excel. Here’s how real data wranglers do it. https://t.co/MwsbgOKyVD
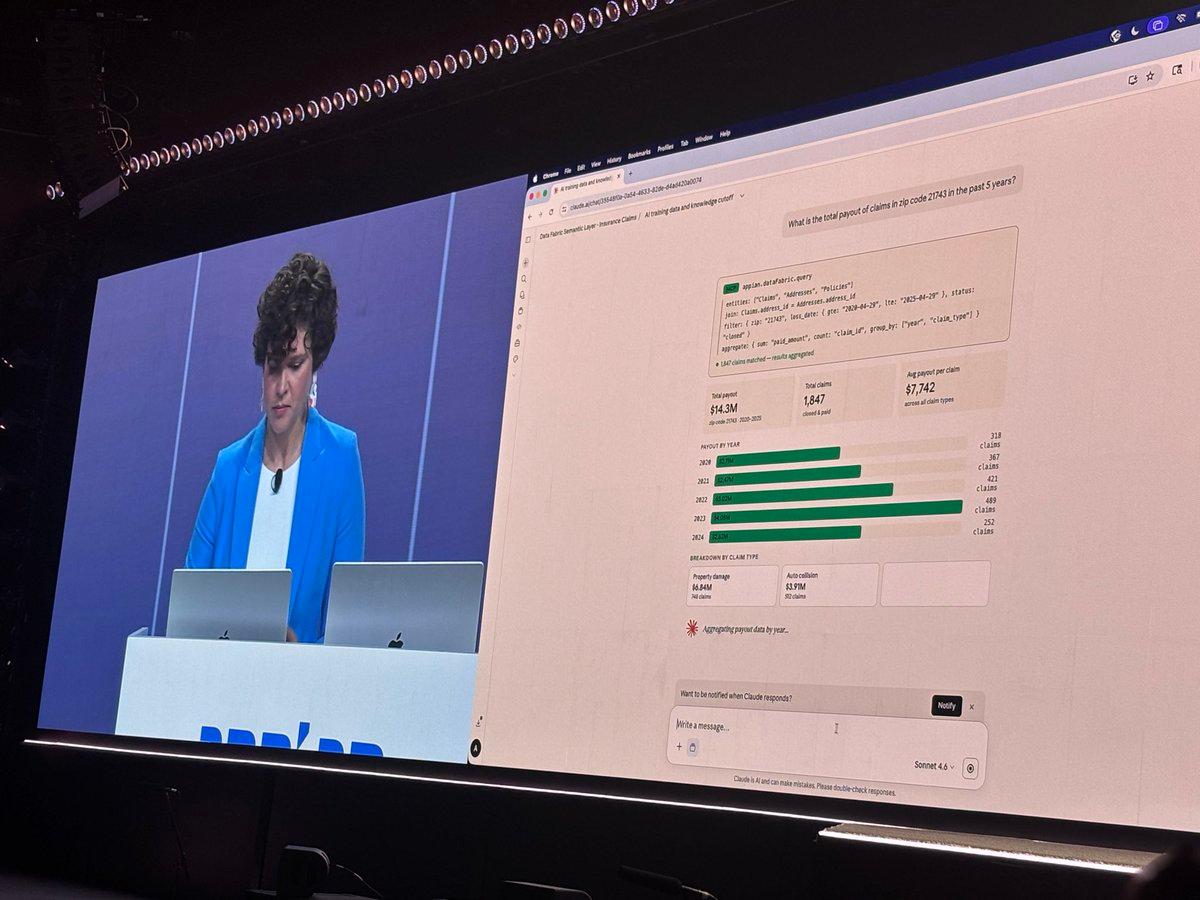
Claude Enables Unified Queries Across Structured and Unstructured Data
Using Claude to query the context layer and data fabric including unstructured documents. #AppianSummit #AI https://t.co/5gozb1CTrJ

Data Fabrics and MCP Must Provide Clear AI Context
Michael Beckley - data fabrics and mcp must deliver clear context to AI agents. #AppianWorld #AI #CIO https://t.co/GOrMSwUFXy

Custom SAP S/4HANA Tweaks Hide Major Risk
Public filings reveal a disconnect: 98% data cleanliness and fitting SAP S/4HANA's standard functionality sound great, but the devil's in the details. Customizations, not standard features, often introduce hidden risks and complexities. #DataGovernance #SAP #ProjectManagement https://t.co/s1WdakdrgC

Governance, Not AI, Drives Triple ROI for Leaders
This week, SAS marks 50 years. Bryan Harris opened the conference with a single frame: SAS was built to close the information gap, the gulf between data and the human capacity to act on it. AI is finally powerful enough...

AI Failures Reveal Data Quality as Critical Priority
Data Quality Assurance broke out this week. Not because anyone got excited about data quality. Because AI deployments started failing. The models were fine. The data wasn't. 18 months later, every serious team is circling back to the unsexy work. https://t.co/6W59KI6Zhb

AI Agents Poised to Dissolve Data Silos with AWS
Will AI agents finally break down data silos? I’m "relatively” optimistic. Jigar Thakkar is talking about how to do this with Amazon Quick #WhatsNextWithAWS #AWS https://t.co/SnP4khetyO

Amazon Quick Unifies Enterprise Data Across Cloud
First announcement: Amazon Quick. A solution to bring enterprise data together. #CIO #AI #Cloud #WhatsNextWithAWS https://t.co/tgebOMT351

Google's LangExtract: Free, Open‑Source Tool Beats $100K Solutions
RIP document extractors. Google just released LangExtract: Open-source. Free. Better than $100K enterprise tools. Here’s what it does: 🧵

Bitemporal Modeling: Managing Data Across Valid and Transaction Times
Valid time vs transaction time. When you need both. Bitemporal modeling handles historical data along two distinct timelines. https://www.ssp.sh/brain/bitemporal-modeling
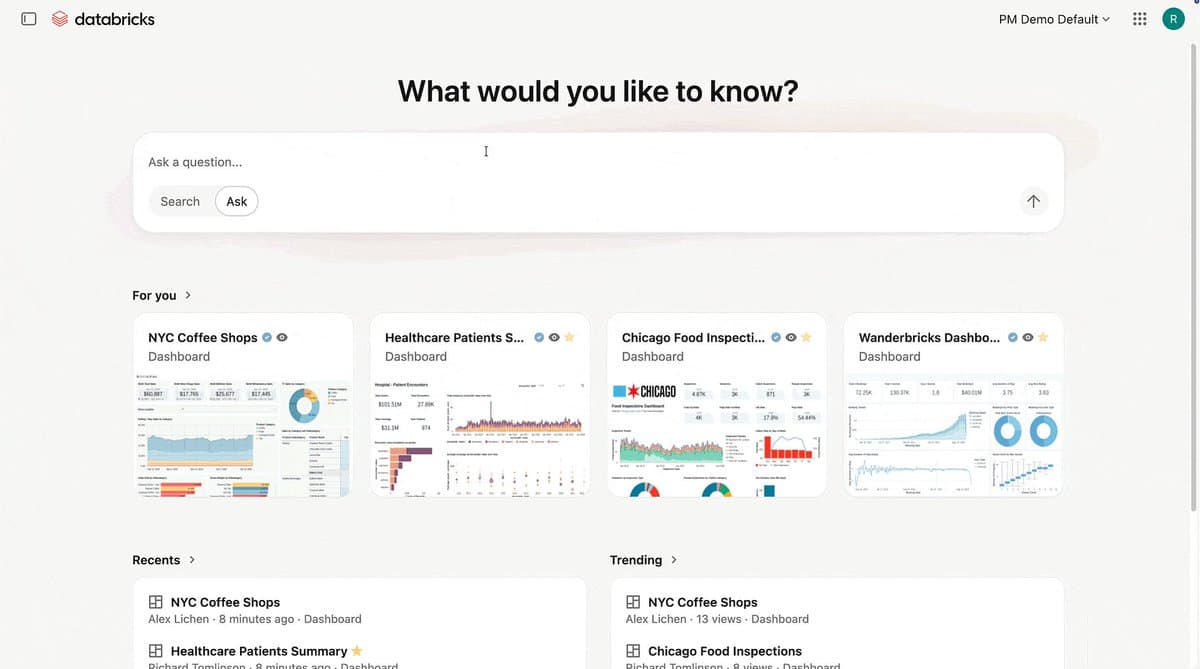
Genie Becomes Databricks’ Core AI for Semantic Analysis
𝐆𝐞𝐧𝐢𝐞 is now the most important way to do data analysis in Databricks. What's unique about it is its ability to extract semantics from your entire Lakehouse, enabling it to answer complex data questions that cripple agents without a deep...

Metadata Is the Database; Data only Works Through It
Metadata is the database. Data is just the thing metadata lets you find, interpret, route, lock, replicate, and recover.

Backfilling: The Mark of a Great Data Engineer
Backfilling is where you see the difference between a data engineer and a great data engineer. A backfill means taking a data asset normally updated incrementally and updating historical parts of it. https://www.ssp.sh/brain/backfill

Structured Data Drives Accurate, Low‑Risk AI Results
#AI is only as good as the structure behind your data. Same model. Two setups. Completely different results. Structured + metadata → higher accuracy, lower risk. Unstructured → messy, inconsistent outputs. That’s the bottleneck most teams ignore. Check out the...

Regulators Target Hotel AI Use Over Data Privacy
Regulators turn attention to hotel AI governance “Hotels are increasingly deploying AI for functions such as … dynamic pricing, and personalised marketing. These systems rely on large volumes of behavioural and transactional data, raising questions about consent, storage, and secondary...

AI Dismisses Data Mesh vs Fabric, Emphasizes Fundamentals
Data mesh vs data fabric was "the battle of the storytellers." Zhamak against the fabriconians. Then AI walked in and wiped both off the map. Storytellers win the round. Fundamentals win the decade. https://t.co/NPDJeWrmaE

OpenAI Triples Web Crawl Scale, Study Reveals
Interested in how OpenAI is crawling (across its user-agents)? Good stuff from Chris Long of Nectiv based on 7B+ log file entries. Some good nuggets of information in the study. https://www.botify.com/blog/openai-tripled-web-crawl

Dataplex Becomes a Dynamic, Always‑on Enterprise Knowledge Catalog
"To address this problem, we are evolving Dataplex into a dynamic, always-on Knowledge Catalog that serves as the universal context engine for your enterprise, helping agents execute complex tasks with accuracy." https://t.co/C1akH2b5yu < I'm listening.
External Tables Persist: Legacy Need Meets Modern Data Access
Have you ever thought why Databricks, BigQuery, and others are still adding features such as External Tables? I've used them when starting my career in 2003, but why are they still used today? And what are the modern versions of...
BI Dashboards Are Dying; Prepare for the Next Wave
RIP BI Dashboards. Tools like Tableau and PowerBI are about to become extinct. This is what's coming (and how to prepare):

From Imperative to Declarative: Rethink Data System Design
Not just syntax. A fundamental shift in how you think about data systems. Imperative: dictate exact steps. Declarative: describe what you want, system figures out how. https://www.ssp.sh/brain/declarative-vs-imperative

Unstructured Data Security Hindered by Visibility Gaps
One of the biggest security challenges with unstructured data is the lack of visibility and lineage as information moves across systems, clouds, and teams." #DataLineage #AI https://t.co/PYomJYHDkY

Data Trust and Transparency Demand Urgent Reform
A cracking podcast with @MrMBrown and @DamianPudner of @GreatBritishTT talking Data: Trust, Transparency, and the Need for Reform https://t.co/fOQA35x2rN

Governance Success Starts with People, Not Tools
Most data governance projects fail because they start with the tool. Not the process. Not the people. Colruyt Group flipped that: they aligned roles, tested the model, then scaled In the AI era, governance isn’t control—it’s enablement. by @ronald_vanloon, Grimme Bogaerts & Martijn...
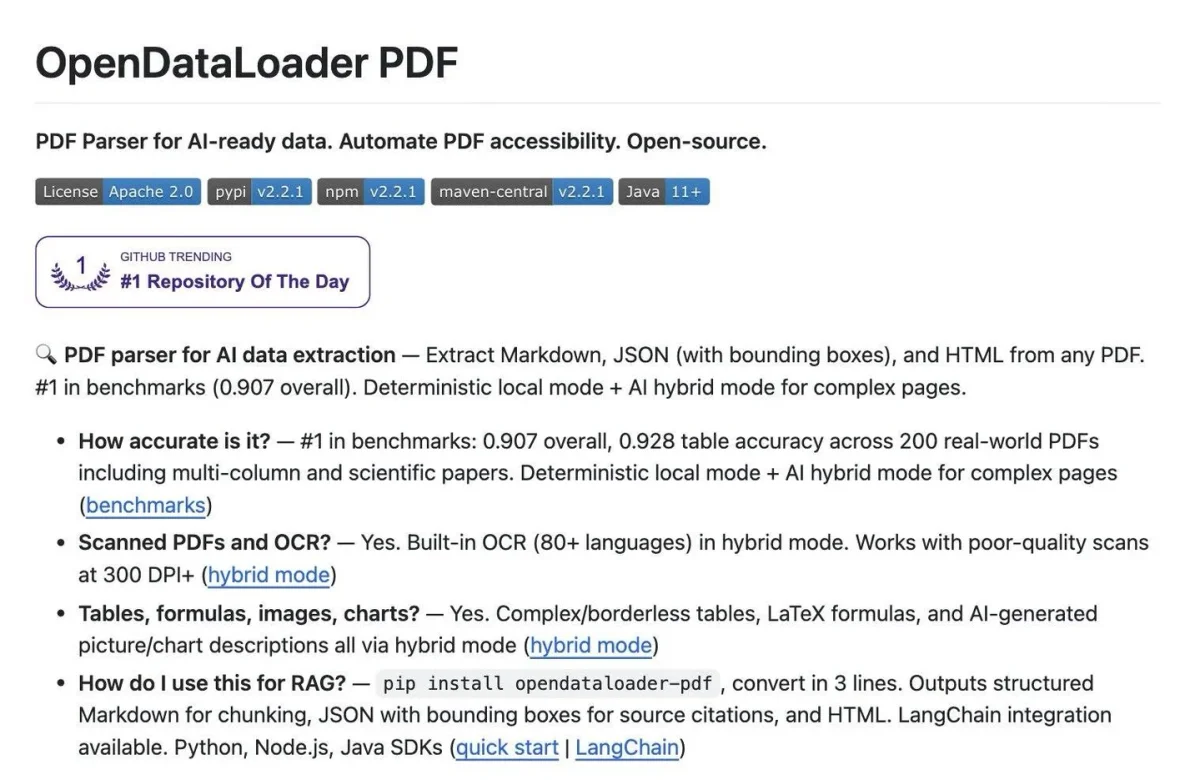
OpenDataLoader PDF: Trending Parser Boosts RAG Pipelines
Someone just open-sourced a PDF parser that converts documents to Markdown, JSON, and HTML — and it's currently the #1 trending repository on GitHub. It's called OpenDataLoader PDF. Here's why data scientists building RAG pipelines should pay attention.

Simple Fixes Like Quantization Beat Proprietary Hype
Once again I learn that: - Everyone is aware of pgvector limitations (filters, perf when doesn't fit in memory) - Vendors use this to advocate for proprietary alternatives - Almost no one talks about the simple solutions: Quantization / halfvec, partitions, partial indexes.
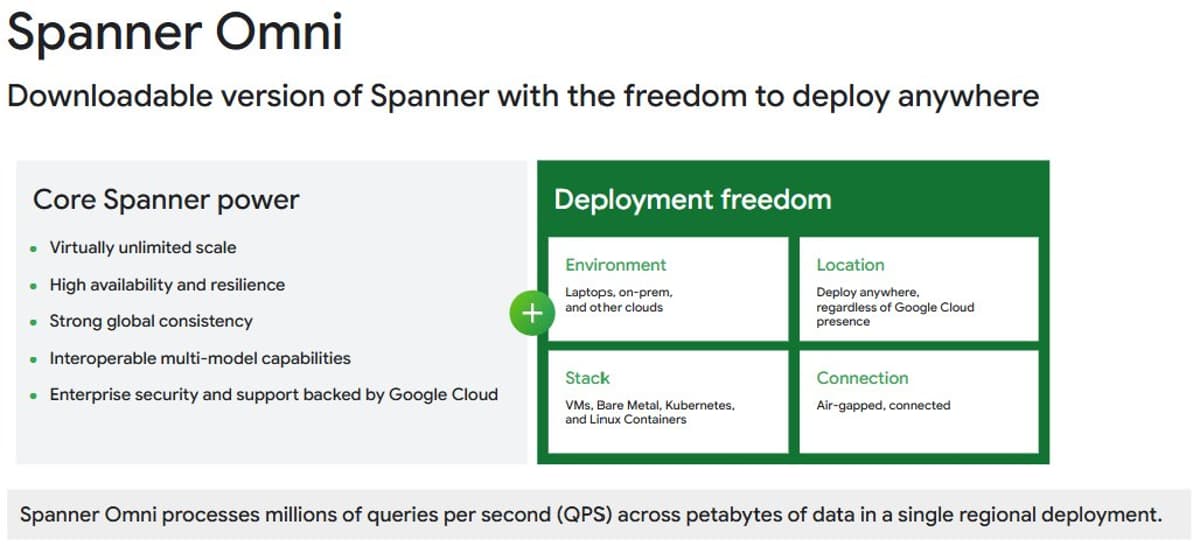
Google Cloud Spanner Omni: Portable, Best‑in‑Class Database Everywhere
The best database on the internet is now available ... anywhere? We just announced @googlecloud Spanner Omni, with reimagined TrueTime and Colossus components for portability. https://t.co/iHBOKF7nH2 Pull the container here: "docker pull https://t.co/g26aVGW0aX" https://t.co/zqU7Z1g3Lp

No Excuse for Type Errors in 2026.
I honestly don't get it. In a few weeks I - by myself - could build a canonical, relational, evolvable, trace-able, PII-cleansed, auditable data architecture merging external and internal data sources with strict permissioning and provenance, with agentic, context-aware retrieval,...

Data Readiness Determines AI ROI Success
#Ad Your AI strategy is only as strong as the data behind it. Cloudera’s latest report, The Data Readiness Index 2026, shows why data access, governance, quality and infrastructure have become critical factors in determining whether AI initiatives deliver real...

AI Transforms Governance of Enterprise Unstructured Data
"Unstructured data now makes up the vast majority of enterprise information, and AI is redefining how organizations bring control, accessibility, and security to it." #DataGovernance #AI https://t.co/PYomJYHDkY
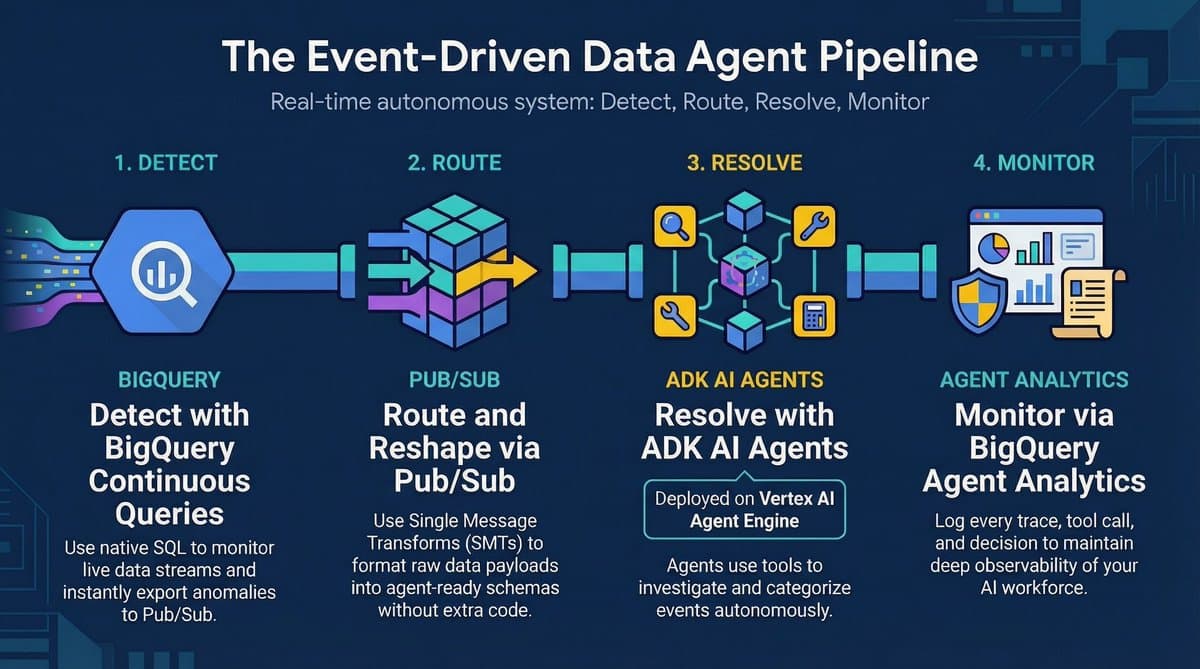
Seamless Hand‑off: Stream Processing to Messaging to AI Agent
Not always, but sometimes the pieces just fit together well. I like this post that shows a clean handoff from : Real-time stream processing --> messaging engine for data transformation --> AI agent that processes the message https://t.co/wGIr7GLVtQ https://t.co/VgaydbuoUW

Embed Governance in Tools, Not Just Policies
Most companies think data governance is about policies and committees. The ones that get it right embed governance into their tools. https://www.ssp.sh/brain/data-governance

Data Governance: Fast‑Pass to Faster, Confident Decisions
Data governance sounds like bureaucracy. In reality, it’s a fast-pass to faster, more confident decision-making. Here’s why it matters more than ever 👉 https://t.co/BXkcbZnc00 @DI_tweet #HIMSS26 #HITSM
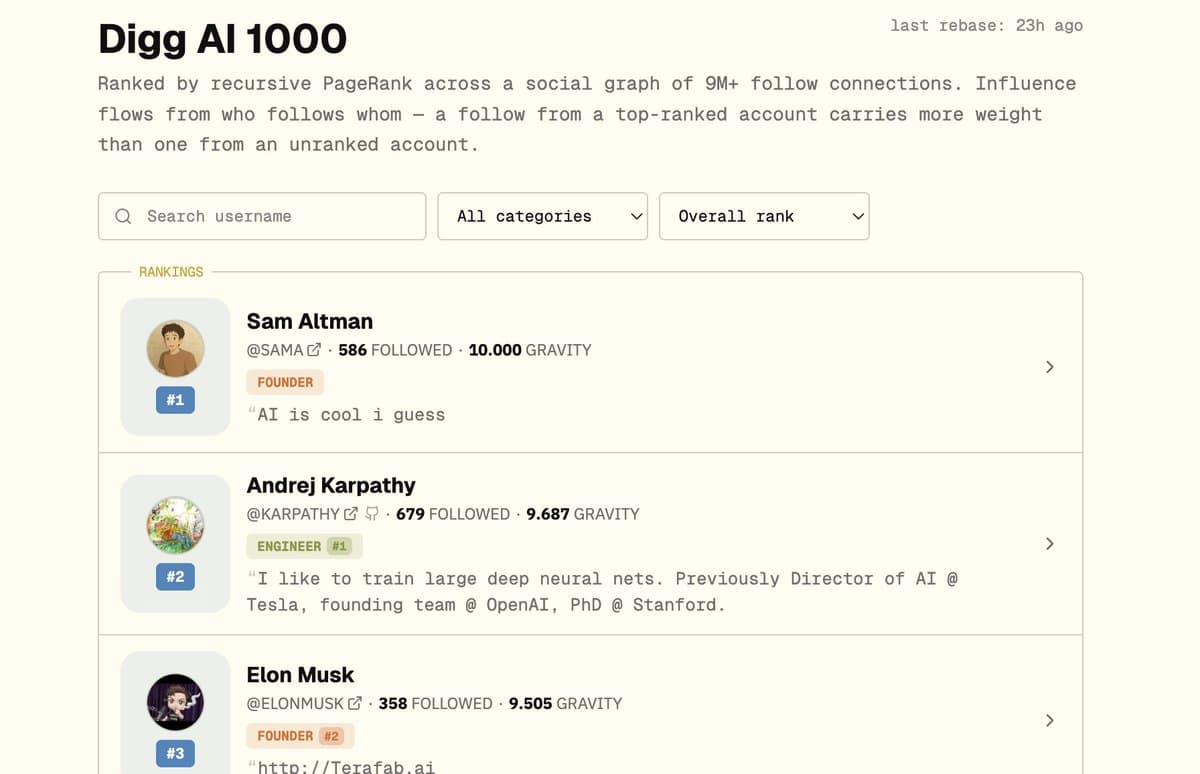
Personalized PageRank Reveals High-Impact Nodes in 9M-Edge Graph
So... "ai, explain what I just did": we ingested 9M+ directed edges from X into a weighted influence graph, then ran a personalized PageRank variant — tuned for human accounts — to surface eigenvector centrality at scale. once you know the...

Data Lakes Gain Full ACID Guarantees Like Traditional Databases
Normally ACID means a database. But now data lakes like Delta Lake added these features too. Atomicity, Consistency, Isolation, Durability. Simple files on S3 now have the same guarantees as Postgres. https://www.ssp.sh/brain/acid-transactions