Data‑rich SaaS Firms Poised for AI‑driven Growth
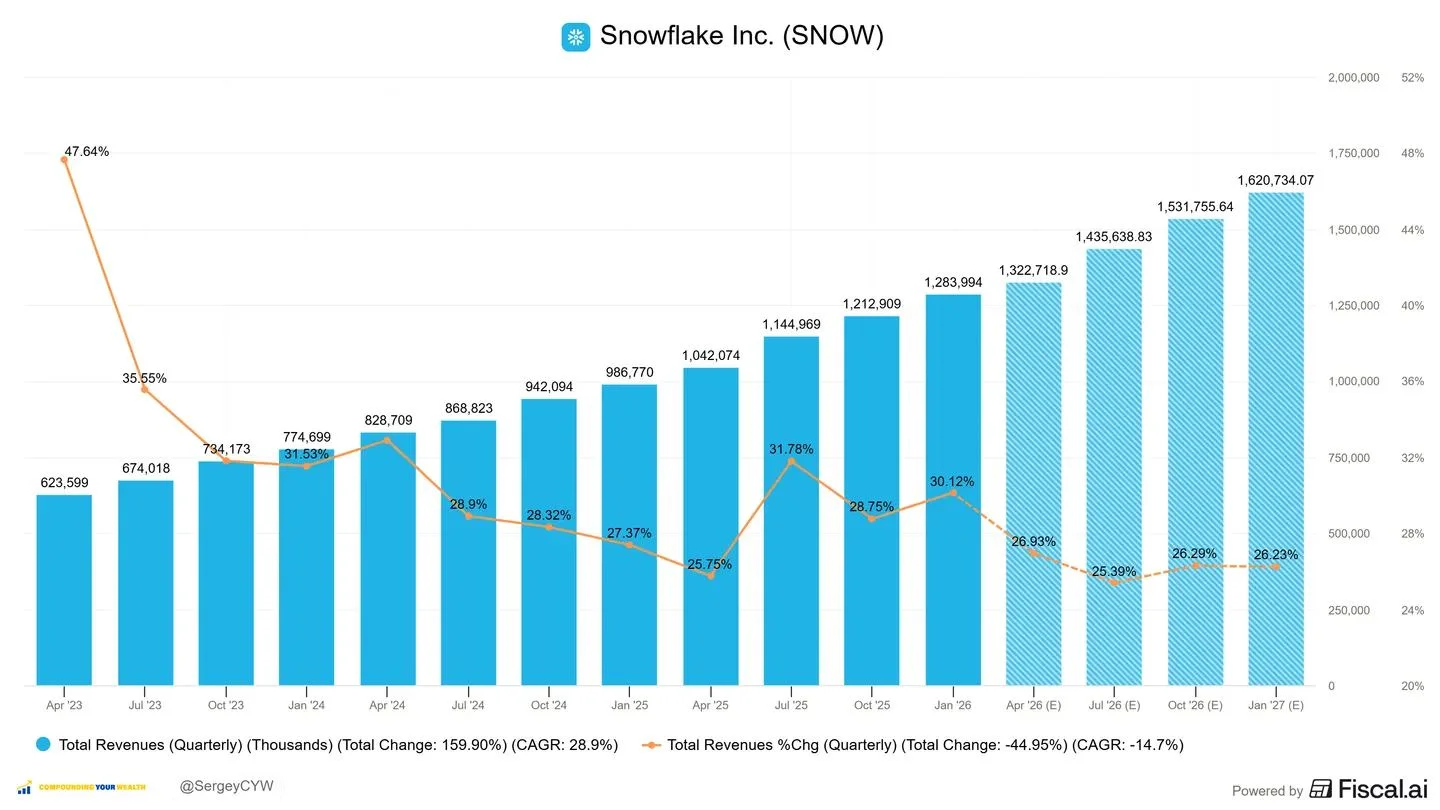
5 fast-growing SaaS companies with strong moats + AI tailwinds 👇 Companies that already own data + distribution are in the strongest position. $SNOW Snowflake | NTM growth +26.2% Snowflake is positioning itself as the core layer for enterprise AI. Tools like Cortex AI and Snowpark allow customers to run models directly on governed datasets, without moving data externally. Over 5,200 accounts are already using AI/ML weekly. Consumption increases as AI workloads scale. Investing

Eight R/CLI Tools Simplify Excel, TSV, CSV Handling
8 R/command line tools to deal with excel, tsv and csv files 🧵 that makes your life easier https://t.co/X3AU0OARmR

Palantir Forces Public Sector Transparency, Threatening Opacity
How many people know that Palantir has always explicitly sought to create an operational environment in which decisions, data, and actions by the PUBLIC SECTOR are so thoroughly recorded and linked that they can always be reconstructed and scrutinized after...

Data Platforms Transform Semiconductor Manufacturing Efficiency
#Technology #Blog #Semiconductor #Manufacturing #Data BLOG-323 | The Emergence Of Data Platforms In Semiconductor Manufacturing: https://www.chetanpatil.in/the-emergence-of-data-platforms-in-semiconductor-manufacturing/

AI Won’t Cure Data Debt, Just Raise Costs
Scott Taylor: "AI is not Ozempic for data management." It will not absorb 20 years of data debt. The hard work doesn't vanish, it just gets a new vendor and a bigger invoice. https://t.co/6uuYvKplh7

Master Fundamentals, Not Fleeting Data Tools
Attention Data Engineers 🚨 Stop chasing every new tool that shows up. Today it’s Snowflake.Tomorrow it’s DuckDB. Next week it’ll be something else. And you’ll always feel one step behind. Here’s what actually compounds: Write SQL so clean that anyone can trust it. Understand how data moves...

Schema Evolution: Add Columns Without Breaking Downstream Consumers
Adding a column seems trivial. Until you realize 47 downstream consumers break. Schema evolution is a pivotal feature of data lake table formats. It enables seamless addition of new columns without disrupting existing structures. https://www.ssp.sh/brain/schema-evolution

Winning AI Firms Clean Data Before Scaling
"Garbage in, garbage out is as irrefutable as gravity." Scott Taylor. AI doesn't change physics. The companies winning with AI fixed the data first. Everyone else is paying NVIDIA to confirm their data is broken. https://t.co/o7kTniQ2Ev

Enterprise Data Strategies Need Balanced Analytics and Reporting
Why Enterprise #Data Strategies Must Balance #Analytics And Reporting by Govinda Rao Banothu @Forbes Learn more: https://t.co/hUJAggO72h #DataScience #BigData https://t.co/vcT5GRd7aR

Governance Is Hobby; Security Is Necessity with Consequences
Data Governance: trending down. Data Security: trending up. Not a paradox. A lesson. Governance without consequence is a hobby. Security with consequence is a necessity. Scared organizations actually do the work. Same underlying work. Different stakes. Different budget. https://t.co/ywusY5rwFp

Qlik Introduces Data Trust Scores for AI Agents
.@Qlik aims to gauge trust of the data underneath agentic AI https://t.co/imj2bAfdYz Qlik is looking to give the data used by AI agents a trust score to make agentic systems more reliable. https://t.co/onnPfAySF1

DevOps Is Becoming Data Engineering’s New Data Science Role
Is DevOps the new data engineering of data science? As in the old days, when you spent 80% of your time on data engineering instead of data science. https://www.ssp.sh/brain/the-state-of-devops-in-data-engineering

AI Accelerates Mid-Market Data Integration for Faster Decisions
Contributor Spotlight: Henry Park (p. 33): AI makes mid-market data integration faster and more accessible - connect systems, improve insight, speed decisions. https://t.co/YrxFqMpTXp #AI #Data #SIOP https://t.co/l3pRT7Y3Zz

Mid‑Market Firms Must Close Compliance Gaps Now
Mid-market regulated firms are sitting on a compliance gap. PHI/PII pipelines built for speed, not governance. DLT expectations. Unity Catalog policies. On-call ownership. Most have one layer. Few have all five. Build it right once. Outrun the audit.

AI Agents Lack Human-Like Skepticism Toward Bad Metadata
Coding agents take bad metadata at face value. They won’t reconcile five different naming conventions for the same entity. They won’t flag that a span is suspiciously short because it timed out silently. This is a fundamental and under appreciated asymmetry: humans...

Qlik Unifies Data, Analytics, and Action for AI
Latest @Qlik tools target helping users achieve AI goals https://t.co/mzrr4bpiUZ @TechTarget @EricAvidon "The real story is not another AI assistant. It is Qlik connecting trusted data products, analytics, data engineering, and action so customers can operationalize...” - @MikeNi @constellationr

Clean Data,
ODI CEO argues data quality, not AI models, is the competitive edge. This favors incumbents like SAP with vast enterprise data over startups. Dirty data leads to 'garbage in, garbage out.' #DataQuality #AIStrategy #EnterpriseData https://t.co/WerM0by3bS

Unity AI Gateway Unifies Data and Agent Governance
If you ask our customers what Databricks' biggest value is chances are that you hear 𝐔𝐧𝐢𝐭𝐲 𝐂𝐚𝐭𝐚𝐥𝐨𝐠. In the last three years, we provided governance for Agents, MCP Servers, Tools/Skills and Unstructured data as part of our AI Gateway. Today...

Atomico’s Data Engine Fuels One‑third of New Deals
What does it take to invest across Europe’s startup ecosystem? @atomico built an internal data engine, using Crunchbase data as its backbone, that powers 1 in 3 new opportunities to instantly review company funding history, & uncover deeper market intelligence. 🔗:...

Production-Ready Lakehouses Needed From Day One
Mid-market companies in regulated industries are moving PHI/PII into analytics lakehouses right now. The ones doing it right build for production from day one. The ones doing it wrong build notebooks they'll have to rebuild. "We'll add governance later" is already behind.

BI Isn't Dead: Dashboards Still Power Enterprise Insights
We've heard it all. BI and dashboards are dead. But every time, only to rediscover its power and resurrection whenever we need grounded data analysis in any enterprise and startup space. https://www.rilldata.com/blog/ai-reveals-why-bi-still-matters-hint-its-not-dashboards

DEAL‑Elsevier Workshops Boost Data Governance Trust in Publishing
Trust in scientific publishing depends on how user data is handled. A series of workshops between DEAL and Elsevier created space for a structured, outcome-focused discussion on data use, governance, and privacy in scientific publishing. Read more: https://t.co/IbjdGuuWhs #data #governance #privacy #scientificpublishing...

Data, Not Models, Limits AI in Biology
The biggest bottleneck in AI for biology isn't models. It's data. @BerkeleyLab is building the infrastructure to fix that: integrated multi-omics datasets, queryable data lakehouses across data types, and high-quality annotated training data for modeling dynamic biological systems. This is DOE-funded, national-scale...

Dropbox Cuts 200 Hours Quarterly with TextQL
Dropbox saved 200 hours per quarter on a single data project thanks to TextQL. A single query can be pushed to all analysts for transparency and consistency. No more blind spots and duplicative efforts for data teams and embedded data scientists.

Eight Data Trends Shaping 2026
The 8 Data Trends That Will Define 2026 Data is evolving fast — these eight trends highlight how organisations will collect, manage and use data in the coming years. Read more 👉 https://lnkd.in/eERGgKDP #Data #Analytics #TechTrends #BernardMarr

Google Cloud Pub/Sub Now Triggers LLMs on Data Streams
Yesterday, I look a look at how @GoogleCloudTech Pub/Sub now makes it easy to invoke an LLM for a data stream. https://t.co/B3CIe7Ugjl @iRomin did a better job of covering this feature in his post last week: https://t.co/VwAd4ggamI

Data Foundations Crucial for Agentic AI, Infor Leads
And the data foundation gets some attention. key in the Agentic AI era. @Infor has a data lake since 2013 or so. #InforAnalystSummit https://t.co/A0nLYhi4by

Apache Arrow Enables Zero‑Copy Cross‑Language Data Sharing
Zero-copy data sharing between Python, Java, C++ without serialization overhead. That's Apache Arrow. Arrow is not a file format. It's an in-memory columnar format. https://www.ssp.sh/brain/apache-arrow

Muse Spark Reveals Century-Long Global GDP Shifts
i find muse spark is very good at data analysis—both finding relevant open-source data and analyzing it. for example, here's my results for analyzing global share of GDP over past century: https://t.co/pD4q7n7mqX https://t.co/xHcZTIgAl4
Databricks‑Microsoft Alliance Underscores Data Platform’s Critical Role
Databricks and Microsoft are moving together right now. The data platform race is not slowing. It's compressing. The model is the DJ. The data platform is the venue. Nobody remembers the DJ when the sound system fails. https://t.co/LgnMfkCvrj

Google Rebrands Looker Studio Back to Data Studio, Adds Pro Tier
🤔 Google has rebranded Looker Studio to ... Data Studio (again)! "Users need a single place to curate and analyze their data from the many different sources that impact their business each day... We are sharing the next...

AI to Rank Judges by Sentencing Impact
Feel like I want to build an AI agent to scrape every Judge’s sentencing history, then cross reference that with court records and arrest records to calculate recidivism rates, then rank the recipients crimes by level of severity/violence, then rank...

AI Masks Bad Data, Making Broken Pipelines Invisible
Snowflake is trending this week. Not because of a new feature. Because AI made broken data transformation pipelines impossible to ignore. An LLM does not know your data is bad. It just makes it sound confident. That is worse than a bad dashboard. At...

Replit Deploys to Databricks, Boosting Enterprise BI Speed
Replit now deploys directly to Databricks. Your apps run inside your Databricks environment while inheriting its security, governance, and data access. Beta is live. Enterprises are already building with it and seeing massive acceleration in BI and internal tools. https://t.co/O33uJHohgo

IBM's WatsonX Powers Masters App, Its Only AI Win
The Masters App is considered best sports app (Netflix execs say it is the best streaming app…after Netflix). A funny subplot: it’s powered by IBM and is basically IBM’s only AI-related win in past 5 years. IBM runs a bunch of ads...

Enterprise AI Agents Must Integrate, Not Operate Alone
Claude Cowork and software vendors The latest agentic AI tools like Claude Cowork are powerful desktop assistants that can handle multi-step knowledge work i.e. researching, synthesising data, creating documents, managing files and running workflows autonomously on your machine. But here's the...
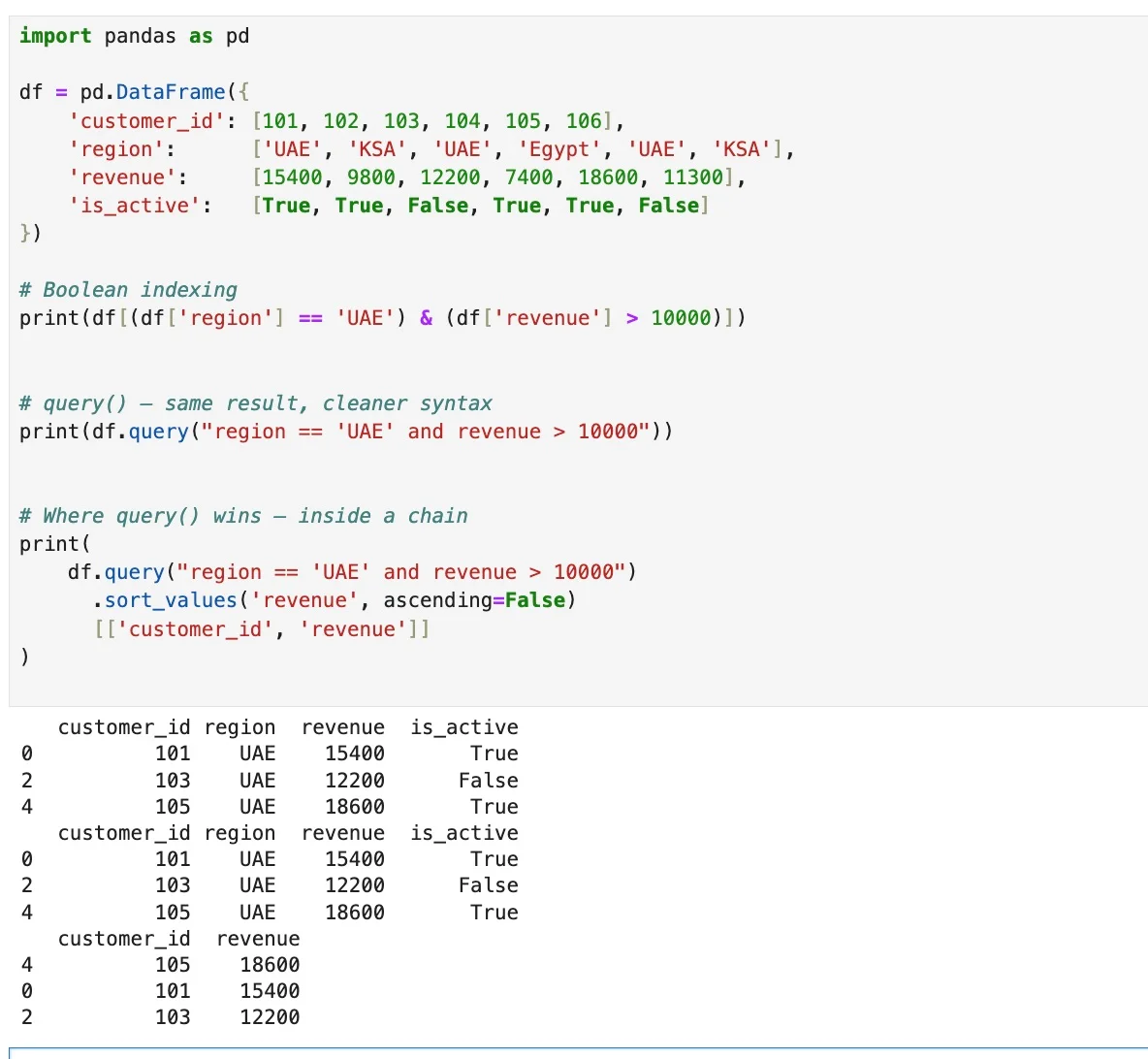
Use Pandas Query() for Cleaner, Chainable DataFrame Filters
Python tip You've been filtering DataFrames like this. df[(df['region'] == 'UAE') & (df['revenue'] > 10000)] There's a cleaner way. df.query("region == 'UAE' and revenue > 10000") Same result. No brackets. No repeated df. Reads like a sentence. Where it really pays off is inside a chain. Use...

New Data Surge Makes Internal Search Essential
90% of the world's data was generated in just the past two years. Discoverability is critical. A data catalog is Google Search for your internal metadata. https://www.ssp.sh/brain/data-catalog

Prefer UNION ALL for Speed; Use UNION only for Deduplication
UNION VS UNION ALL in SQL UNION deduplicates every row after combining the results. That means sorting, comparing, discarding. On large tables that's a real performance cost -- and most of the time, you don't even need it. UNION ALL stacks the...

Business Queries Demand More than Basic SQL Skills
There is a gap between knowing SQL and knowing enough SQL to answer the questions a business actually asks. "Show me each customer's rank within their segment." "Give me a running total of revenue by month." "Flag anyone earning above their...

Enterprise Data Health Check: Are Context Graphs Worth Trillions?
Enterprise hits and misses - time for an enterprise data health gut check. Plus: are context graphs a trillion dollar enterprise play? https://t.co/cH2SNwF5A2 by @jonerp. #EnSw
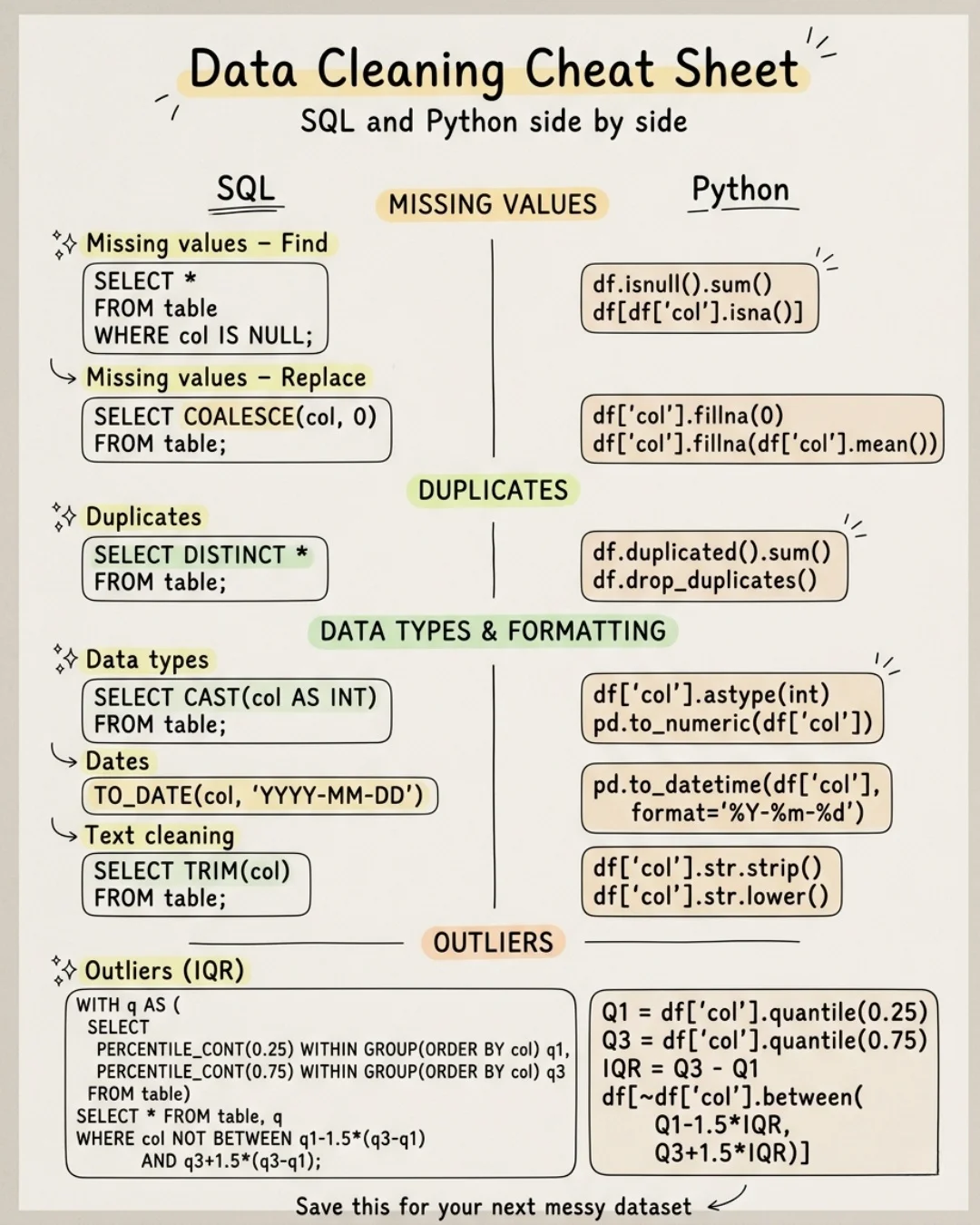
Data Cleaning Is Core Analysis, Not Just Prep
I’ve never worked with a clean dataset. Every real project = messy data. And it always comes down to 4 things: • Missing values • Duplicates • Data types & formatting • Outliers Cleaning isn’t a “prep step”. It is the analysis.

Open‑Source Data Stack Cuts Costs for Mid‑Scale Companies
Full open-source stack for running at low cost for mid-scale companies. Such as Dagster + DuckDB + dbt + Airbyte. https://www.ssp.sh/brain/open-data-stack

Knowledge Graphs Unify Data, Accelerating Informed Decisions
Fragmented datasets still slow many decisions inside organizations. Knowledge graphs connect entities across systems and expose hidden relationships, so leaders can interpret signals with greater clarity and translate data structure into operational choices. Microblog @antgrasso https://t.co/O2qh7Pgcu8

Unified Data Taxonomies Prevent AI Hallucinations, Artemis 2 Shows
Artemis 2 isn't just about space exploration; it's a critical lesson in the #ExecutiveCostOfBadData. Just like astronauts need a shared language for lunar data, enterprises need high-fidelity data & unified taxonomies to avoid #AIHallucinations. Crucial insights for leaders deploying AI!...

Enterprise Data Strategies Need Balanced Analytics and Reporting
Why Enterprise #Data Strategies Must Balance #Analytics And Reporting by Govinda Rao Banothu @Forbes Learn more: https://t.co/hUJAggO72h #DataScience #BigData https://t.co/P8RUw08Wr8

Kimball’s Dimensional Modeling Still Guides Business Process Design
30 years later, Kimball's facts and dimensions and conformed dimensions transcend tooling. Dimensional modeling emphasizes identifying key business processes first, then progressively adding more. https://www.ssp.sh/brain/dimensional-modeling

Data Mesh: A Human‑Centric Network, Not Just Architecture
Data mesh or mesh of humans? Done well, data mesh IS a network of humans. #DataMesh #DataGovernance https://t.co/18gW4z1eAd

Validate Data Loads Instantly with SQL EXCEPT
SQL tip You ran a load job overnight. How do you know every record made it? Most people recount rows and hope the numbers match. There's a cleaner way. SELECT order_id FROM staging.orders EXCEPT SELECT order_id FROM production.orders; If this returns nothing, every order transferred successfully. If...

Ignoring Data Governance Leads to AI Project Failures
Data governance isn't cool or sexy. That's why nobody talks about it on the record. Meanwhile their AI projects keep failing. #DataGovernance #AI https://t.co/AAKL6A7DLM