
Universal Semantic Layer Needed for Multi-Tool Data Access
The semantic layer isn't new. SAP BusinessObjects had one in 1991. What's new is the need for a universal semantic layer that works across BI tools, notebooks, and applications. When you only had one BI tool, that tool's semantic layer was enough. Now that data touches 10 different consumers, you need something central. That's the real driver behind modern semantic layers like Cube or the dbt semantic layer. https://ssp.sh/brain/semantic-layer

DataOps Engineers: The Underrated Backbone of AI Efficiency
The most underrated AI role right now: DataOps Engineer. Not the ML engineer. Not the data scientist. The person who designs automation and testing infrastructure that makes everyone else dramatically more effective. Infrastructure that runs without you. That's the whole job. https://t.co/Cng5iC1BEB
IBM Joins Data Platform Race with Confluent Acquisition
With the latest acquisition of Confluent by IBM, they follow up on the Fivetran, Databricks, and Snowflake stack. Or what do you think? With the latest acquisition in data engineering, it's a race of who gets the most complete data platform...

Orchestration Turns Data Stack Flexibility Into Cohesion
The Modern Data Stack promised best-of-breed tools that work together seamlessly. The paradox: the more tools you pick, the more integration work you create. One perspective I find helpful: Orchestration as the connective tissue. A good orchestrator doesn't just schedule jobs -...

IBM Acquires Confluent to Power Real‑time Enterprise AI
.@IBM Completes Acquisition of Confluent, Making Real Time Data the Engine of Enterprise AI and Agents https://t.co/QqwqJPCT4P >> Congrats. A key augmentation for the IBM AI capabilities. Good news for customers. #NextGenApps https://t.co/aCKH7wuesW

Free Datasets + LLM Queries on Snowflake, BigQuery
Snowflake and BigQuery have free datasets you can use to practice SQL with real data. Even better: LLMs are integrated, so you can query in natural language.

AI Adoption Demands Stronger, More Responsive Data Foundations
As AI moves to core operations, pressure on the data layer also intensifies. I canvassed leaders on the work required to build a well-functioning data environment responsive to today’s AI initiatives. (My latest in Database Trends) https://t.co/X8ar2pKnTZ @BigDataQtrly

BigQuery Studio Gains Context‑Aware Editing and AI Discovery
We just turned on some new smarts in the @googlecloud BigQuery Studio interface. Now you get context-aware query editing (sees open query tabs), better resource discovery through natural language questions, and smarter troubleshooting. https://t.co/9ekJhzv0Ki https://t.co/SNntL6X6bB
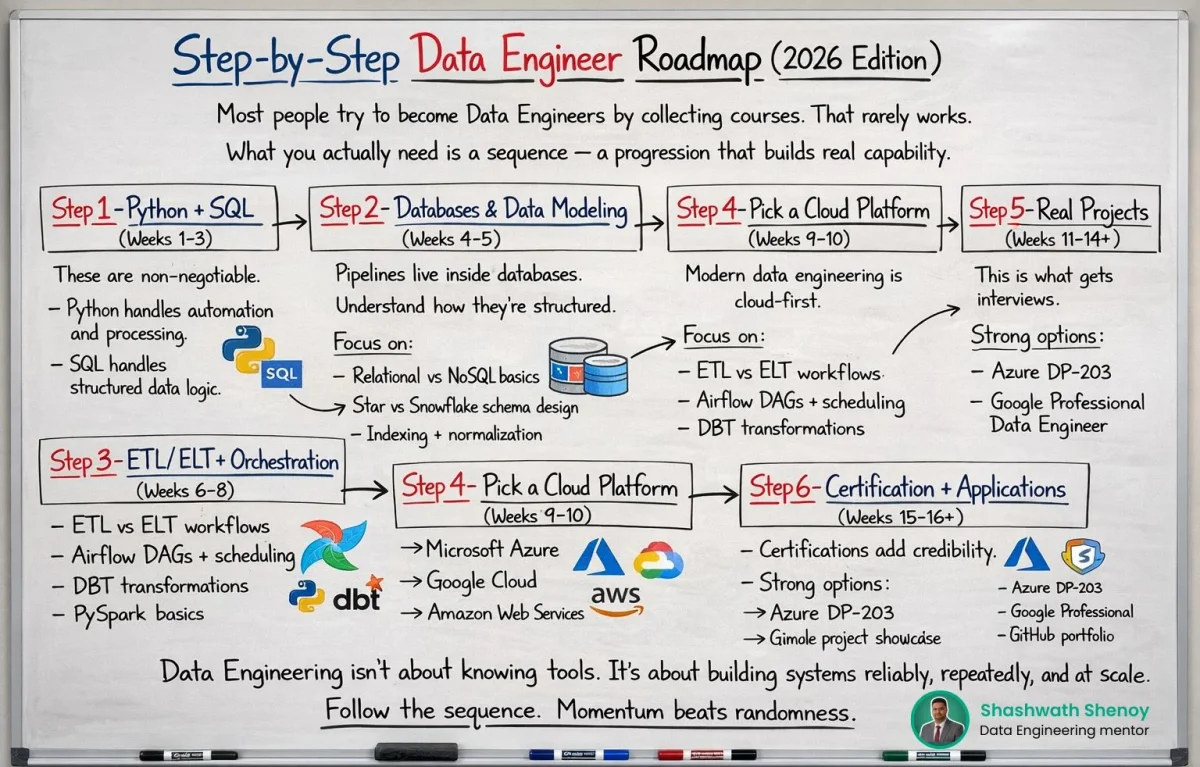
Follow a Structured Roadmap, Not Random Courses, to Engineer Data
𝐒𝐭𝐞𝐩-𝐛𝐲-𝐒𝐭𝐞𝐩 𝐃𝐚𝐭𝐚 𝐄𝐧𝐠𝐢𝐧𝐞𝐞𝐫 𝐑𝐨𝐚𝐝𝐦𝐚𝐩 (2026 𝐄𝐝𝐢𝐭𝐢𝐨𝐧) Most people try to become Data Engineers by collecting courses. That rarely works. What you actually need is a sequence a progression that builds real capability. Here’s a practical 6-stage roadmap that takes you from foundation → job-ready 👇

Pick Data Modeling Pattern Based on Needs, Not One‑Size
I think about data modeling patterns in four main categories: 1. Dimensional modeling (Kimball) - optimized for queries 2. Data Vault - optimized for auditability and change 3. One Big Table - optimized for simplicity 4. Medallion Architecture - optimized for incremental refinement No pattern...

CTEs Turn Complex SQL Into Readable, Maintainable Code
SELECT, FROM, WHERE and JOINs will get you started. Then the work gets complicated and you realise tutorial SQL and production SQL are two very different things. Here's level 2 CTEs — readability I was lost in my own nested subqueries. Couldn't follow...
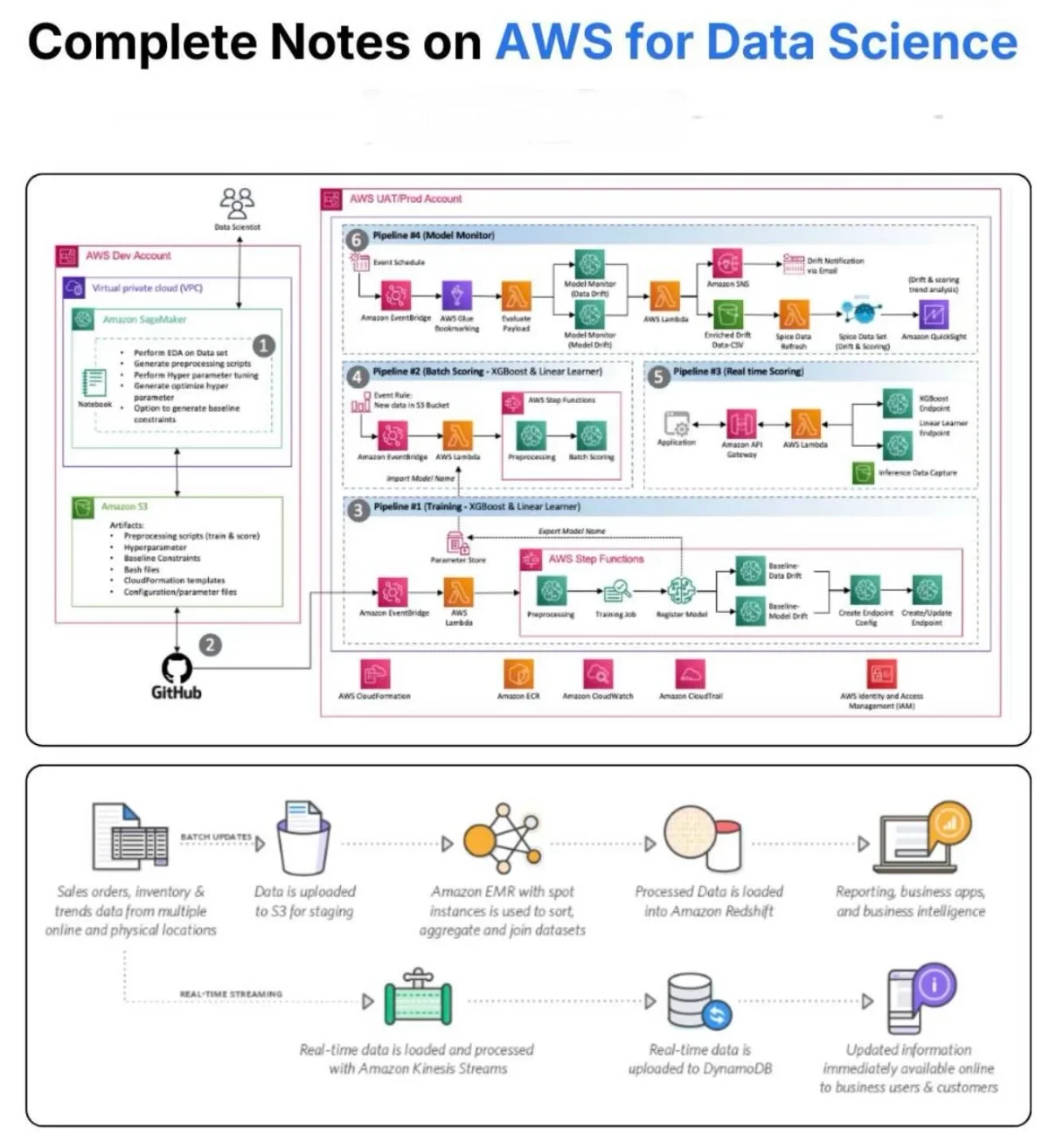
Build End‑to‑End ML with AWS: Glue to SageMaker
A real AWS Data Science pipeline looks like this: Raw data → S3 ETL → AWS Glue Query → Athena Training → SageMaker Deployment → Endpoints Monitoring → CloudWatch Add streaming with Kinesis and orchestration with Step Functions, and you have a full production ML platform. This is...

Generative AI Adds Interpretive Layer to US Strike Planning
Though the US military's big data initiative Maven has sped up the planning of strikes for years, the comments suggest that generative AI is now adding a new interpretative layer to such deliberations.

Effective Data Lineage Connects SQL and Python Pipelines
Data lineage traces your data's journey from source to destination. Where did this number come from? What would break if I changed this table? Who's using this data? Good lineage answers these questions. Bad lineage makes you grep through code. Tools like dbt...

Explore Pipe Syntax in BigQuery Sandbox for Free
Have you tried out pipe syntax instead of traditional SQL? I've only messed around with it a bit. I can see how it's an improvement for different types of queries. This post shows you how to try it out (at no...

Responsible AI Starts with Zero‑Trust Data Governance
RT You can't have responsible AI without responsible data. Classify AI data, extend zero trust, encrypt in use, and spell out non-negotiable governance policies from day one. #AISecurity #DataGovernance @Star_CIO https://t.co/aiB5P99ido

SAP BTP Enables Seamless Cloud Migration with Clean Core
SAP's BTP platform streamlines cloud migrations by offering tools for data quality, master data management, and analytics. It supports a 'clean core' approach, enabling organizations to differentiate with custom processes without complex upgrades. #SAP #CloudMigration #BTP https://t.co/94wouRrLLt
Dynamic Query Pattern Enables Immediate, Flexible Data Retrieval
Big news, I added a new design pattern chapter, called «Dynamic Query Design Pattern». This design pattern problem statement goes like this: 1. Provide immediate answers 2. How you model it matters 3. Dumping everything into the lake is painful The core challenge is enabling...

Validate Data at Source: Shift Left for Quality
"Shift left" comes from software engineering - finding bugs earlier in the development process. In data, shifting left means: validate data at the source, not after it breaks your dashboard. Instead of hoping bad data doesn't show up in your warehouse, you...

SQLMesh Adds Semantic SQL, Auto-Dialect Translation for Dbt
SQLMesh takes dbt's concept and adds semantic understanding of SQL. It parses SQL statements, translates between dialects automatically, and offers compile-time validation. Built by Tobiko Data (now Fivetran). If you're starting fresh, it deserves serious consideration. https://www.ssp.sh/brain/sqlmesh

Built 15‑Year Data Hub in 5 Hours, Beats Meltwater
I had a good friend tell me the apps I created were trash because I didn't have a formal database. I took that as a challenge. In 5 hours, I personally built, populated, and deployed a database containing all the content...

CLI‑first Analytics: DuckDB, MotherDuck, and Rill Empower Agents
CLI-first is eating development. Email, calendar—they all have CLIs now. Why not your business metrics? For data/analytics engineers building with agents: DuckDB + MotherDuck + Rill give you an agentfriendly, #localfirst frontend—exact context via SQL and YAML. https://www.rilldata.com/blog/building-an-agent-friendly-local-first-analytics-stack-with-motherduck-and-rill

Data Fabric: Essential for Modern Data Management Efficiency
Understanding #Data Fabric is Key to Modern Data Management and Efficiency by @antgrasso #DataScience #BigData https://t.co/6OxSioKNji

Think in Assets, Not Jobs, for Data Reliability
Dagster's key innovation is software-defined assets. Instead of: "Run this job on a schedule" You declare: "I need this table to exist, here's how to build it" The difference is subtle but profound. Assets have identities, dependencies, and history. Jobs are just tasks. When...

Turn Data Projects Into Portfolio‑Ready Workflows
Imagine a place where you could: • Pick a data project • Follow a structured workflow • Build something real • Add it straight to your portfolio That's the direction we're exploring.

Anthropic Could Break Slack’s Restrictive Data Policies
Slack is the most important text data source in most companies, but it has the worst data access policies in enterprise software. The only thing that will fix it is competition, and Anthropic is the right company to do it....

Template‑Based Pipelines Offer Flexibility, Demand SQL Skill
I spent years working with data warehouse automation tools before the modern data stack existed. The biggest lesson? There are two approaches to generating pipelines: Parametric - you define parameters, the tool generates SQL Template-based - you write SQL templates with variables Most modern...
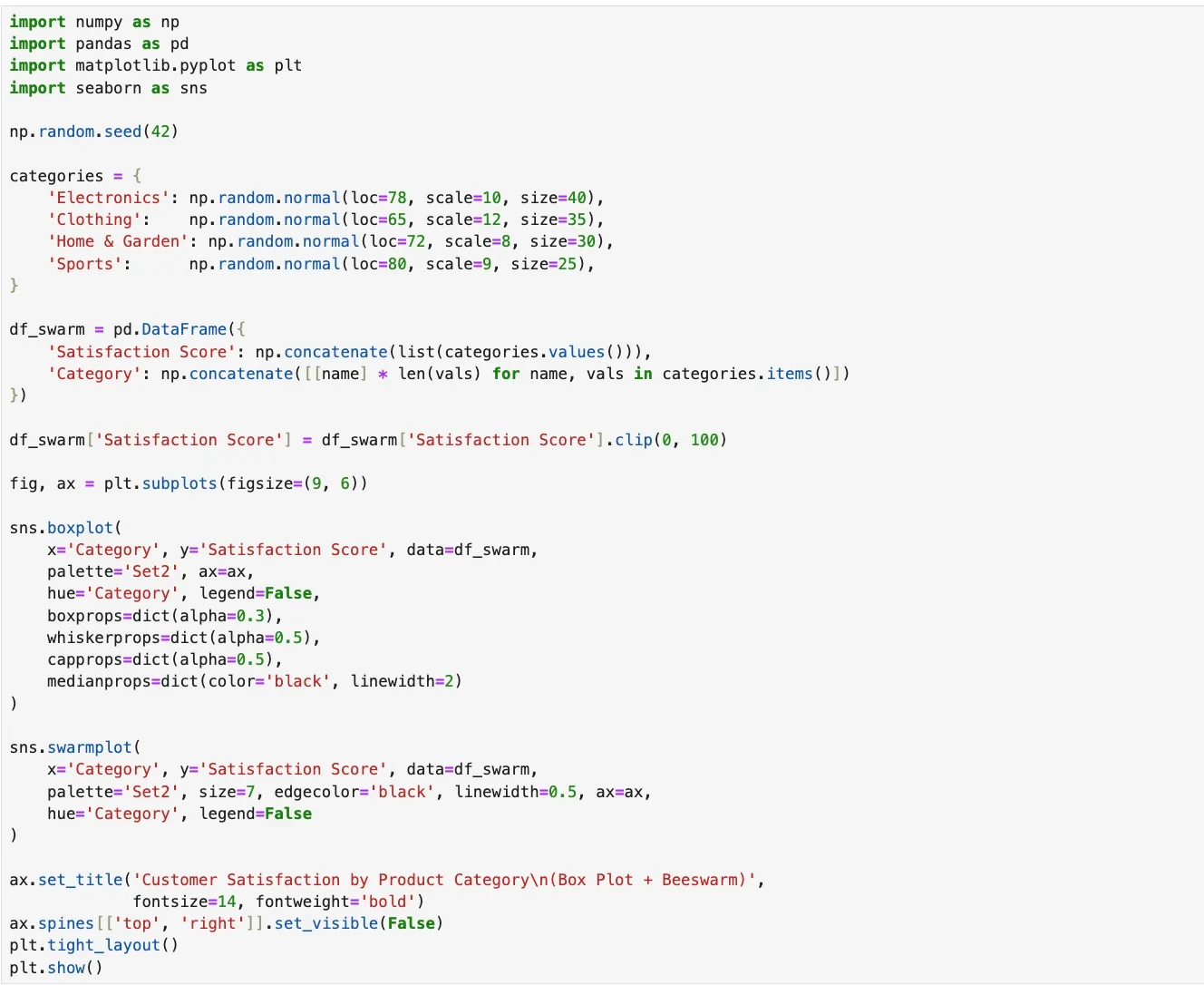
Beeswarm Plots Reveal Hidden Data Clusters Beyond Box Plots
Part 3 of 3 underused chart types worth knowing. A box plot with 15 points looks identical to one with 1,500. You lose all sense of where measurements actually cluster. Beeswarm plots fix this. Every data point is visible. Nothing gets absorbed into...

Most AI Failures Stem From Data Quality, Budget Unknown
Question for your next meeting: "If 95% of AI projects fail before production, and the reason is data quality, what percentage of our AI budget goes to data quality and governance?" The follow-up that makes it uncomfortable: "How confident are we that...

Finance Leaders Stress Data Foundations Over Analytics
Most FP&A teams don’t struggle with analytics. They struggle with data. 💡Finance leaders from PepsiCo, BILL, and Workday shared how they build strong data foundations and a single source of truth to enable AI and predictive decision-making: https://t.co/FnD9BnrjT6 #fpatrends

All Cloud Infrastructure Booms as Data Demand Explodes
AWS and Azure both surging simultaneously. Oracle climbing. Elasticsearch tripled. It's not one cloud winning. It's ALL infrastructure growing as data demand outpaces capacity. The foundation layer is on fire.
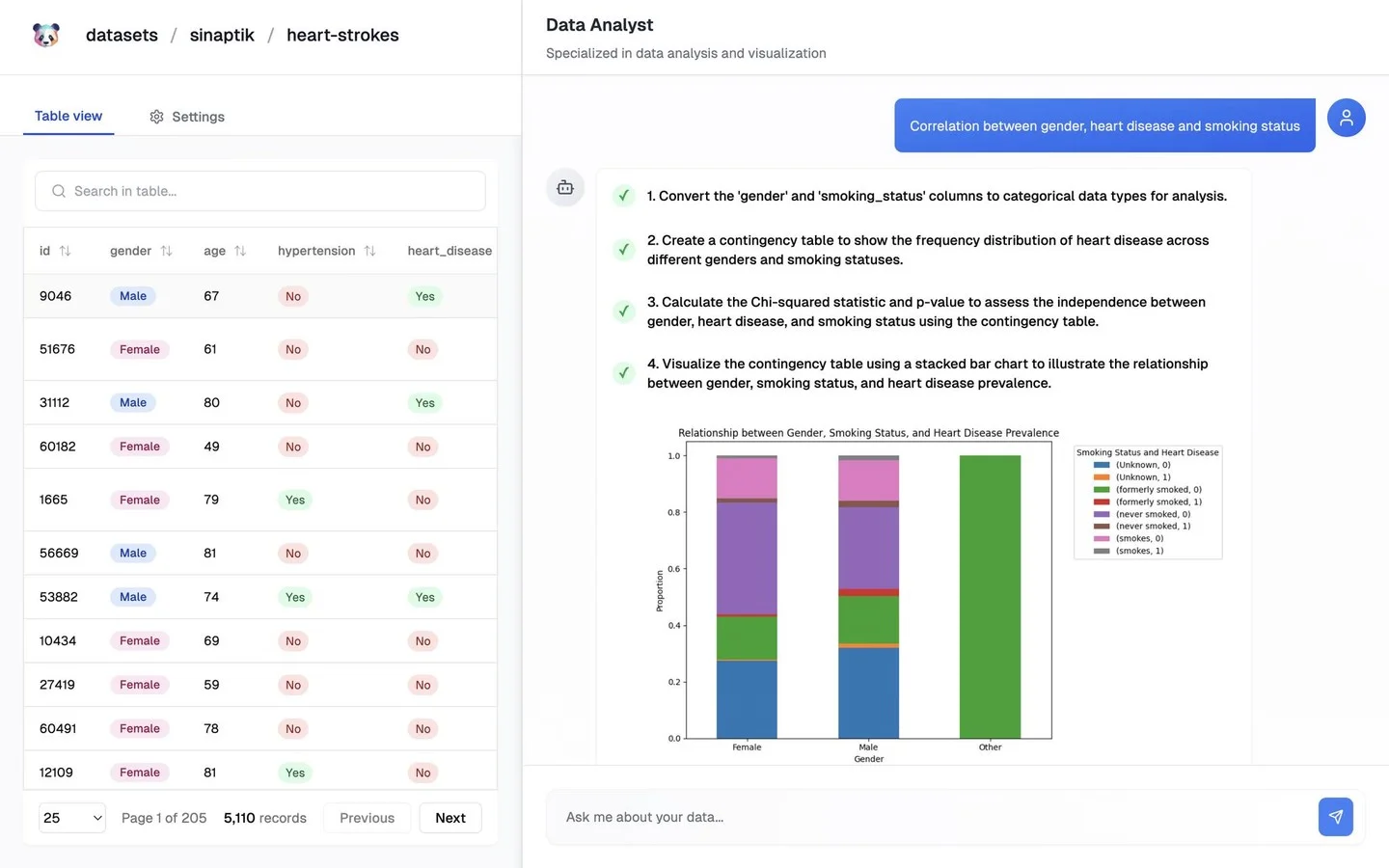
PandasAI: Free, Fast BI Replacement for Tableau
Tableau is about to die. Introducing PandasAI, a free alternative for fast Business Intelligence. Let dive in:

Future‑proof AI: Learning Ability Outweighs Launch Accuracy
Why the most valuable AI systems are not the most accurate ones today, but the ones designed to learn tomorrow In the early days of enterprise AI, success was measured in a single moment: the model launch. A team would...

GenAI Unifies Multicloud Data to Tame Chaos
"Multicloud chaos is fundamentally a data problem, and genAI's edge is building a unified semantic layer over configs, logs, schemas, and lineage." #SRE #Cloud #CIO https://t.co/vBzM21vM14

Use Focused Context Vaults, Not Whole Data, for AI
Everyone's talking about "second brain" for AI. I added a new layer to mine. I built a context vault with 200-700 line summary docs of big areas of my life (business, 2026 goals, family, friends, a personal constitution). WAY fewer...
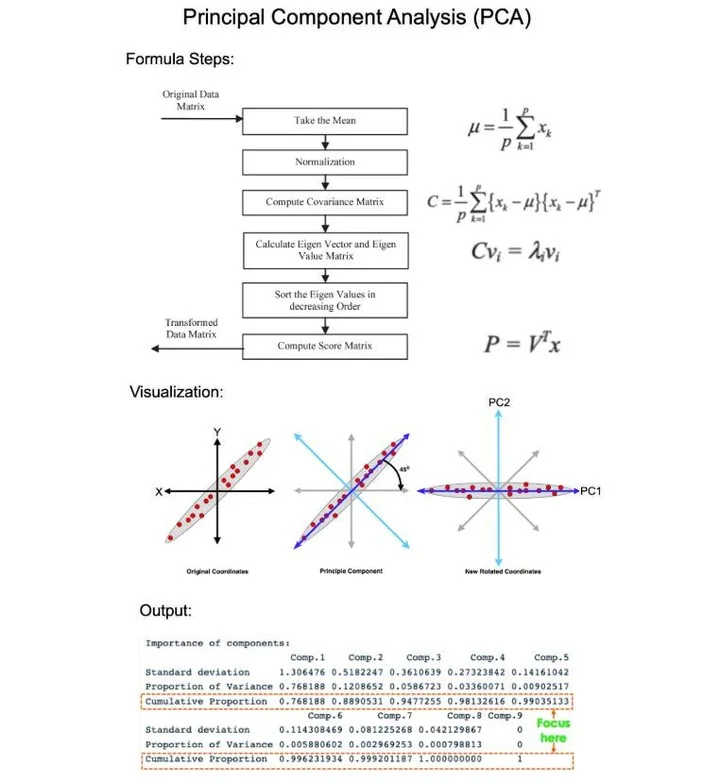
Demystifying PCA: The Gold Standard of Dimensionality Reduction
Principal Component Analysis (PCA) is the gold standard in dimensionality reduction. But PCA is hard to understand for beginners. Let me destroy your confusion:

Natural Language Joins Still Feel Confusing for Beginners
Yesterday I showed someone how to join tables in Snowflake using natural language no SQL required. And she still said it was hard and confusing.
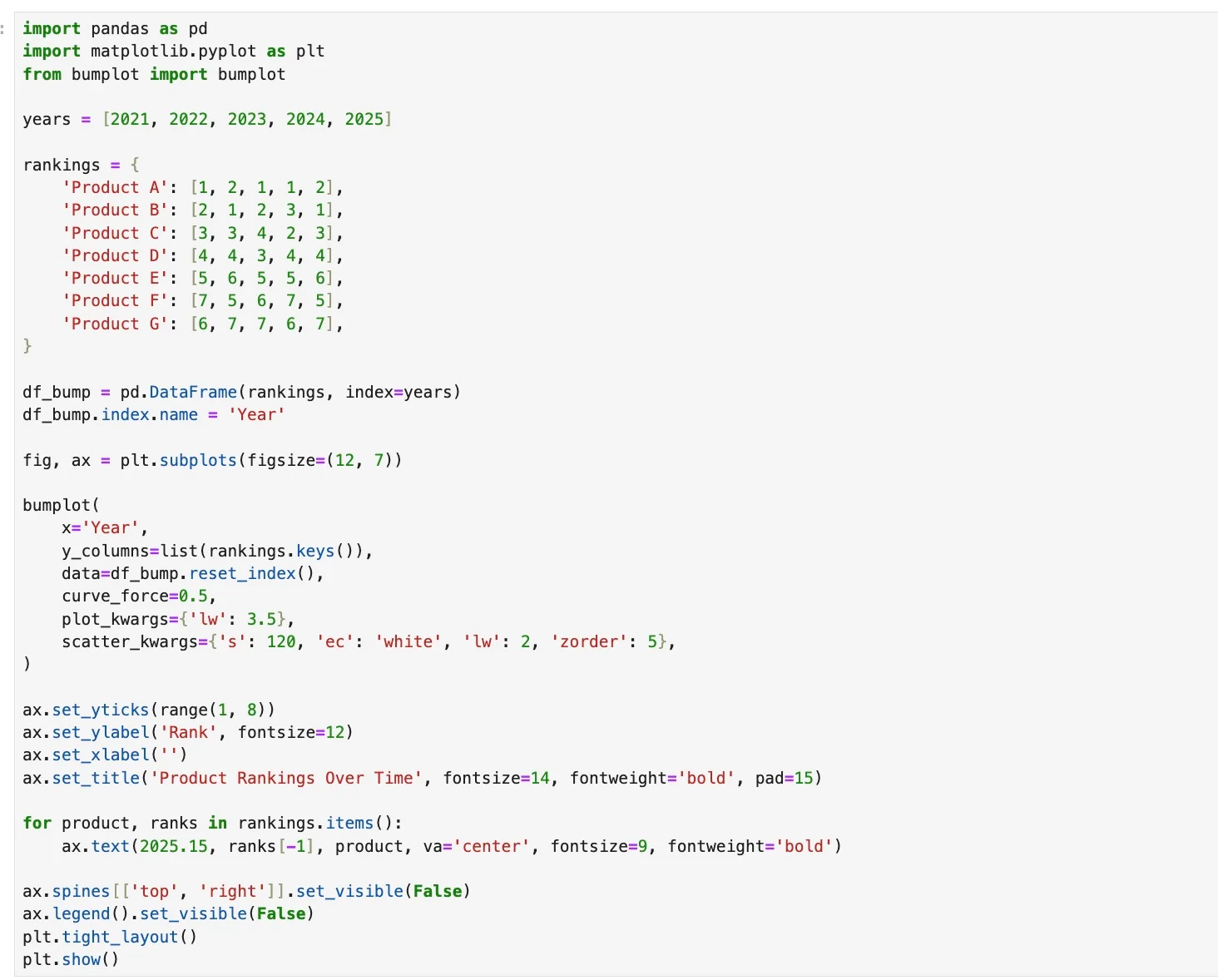
Bump Charts Simplify Ranking Changes over Time
Part 1 of 3 underused chart types worth knowing You reach for a line plot to show ranking changes over time. The lines cross. It turns into spaghetti. Bump charts fix this. When you care about relative position — not raw values —...

Databricks RTM Beats Flink, No Batching Needed
#1 thing people don't know about Databricks and Apache Spark: the performance of Real-Time Mode (RTM), it's faster than Apache Flink and more robust. No more batching.

Boost Pandas Performance with Modin, Dask, Polars
Python Tip When pandas is too slow, there are other libraries to rescue: - Modin - Easiest switch from pandas Change one line: import modin.pandas as pd Same syntax. Uses all CPU cores - Dask - When data > RAM Processes data in chunks across CPU...

Replace UNION ALL with GROUPING SETS for Faster Aggregations
Stop Writing UNION ALL for Multi-Level Aggregations You need regional totals AND product totals AND grand totals. So you write three separate queries with UNION ALL. There's a better way: GROUPING SETS. UNION ALL - Scans the table 3 times. Slow. GROUPING SETS - One...

Introducing the Gwenchmarks Manifesto: Learn Benchmark Mastery
Folks asked me "what's your plan for gwenchmarks"? At first, it was a joke. But... teaching people how to plan, execute and read benchmarks is a good goal. So I wrote The Gwenchmarks Manifesto as a start. Still a bit...

Metadata‑Driven MRR Schedules Unlock Revenue Intelligence
As I was building my MRR analysis feature, I realized that there is much more power in our MRR schedule than we realize. With the correct metadata, we have a revenue intelligence engine that will provide more insight for our...
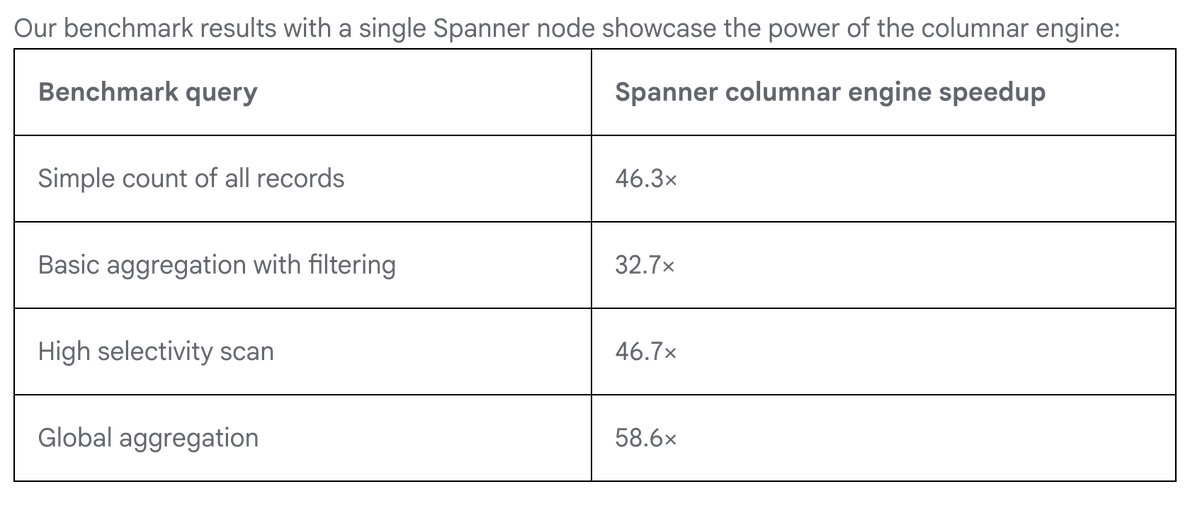
Spanner Adds Iceberg Lakehouse Support with 200× Faster Scans
"The columnar engine uses a specialized storage mechanism designed to accelerate analytical queries by speeding up scans up to 200 times on live operational data" The new @googlecloud Spanner capability means you can serve Iceberg lakehouse data ... https://t.co/dxmgEAI0cA https://t.co/TUe0vNnzfN

Effective Data Strategy Needs Governance, Not Just Storage
A strong data strategy is more than storage. Its context, quality, & governance. The “useless” data may hold insights GenAI needs, but without curation, access controls, and trust, innovation risks becoming noise instead of value. https://t.co/ParkENiwRg

DuckDB Lets You Query 10GB Parquet Locally, Ditch Clusters
There's a moment in every data engineer's career when they discover they can query a 10GB Parquet file on their laptop in seconds. That's the DuckDB moment. It changes how you think about what requires a cluster and what doesn't. Spoiler: most...

Query CSVs Directly with DuckDB—No Load, Faster
Instead of loading CSVs into pandas just to run one query, you can use DuckDB to run SQL directly on files. No loading. No waiting. Just query the file and get results. It’s also 20x faster and uses way less memory. Here’s how...
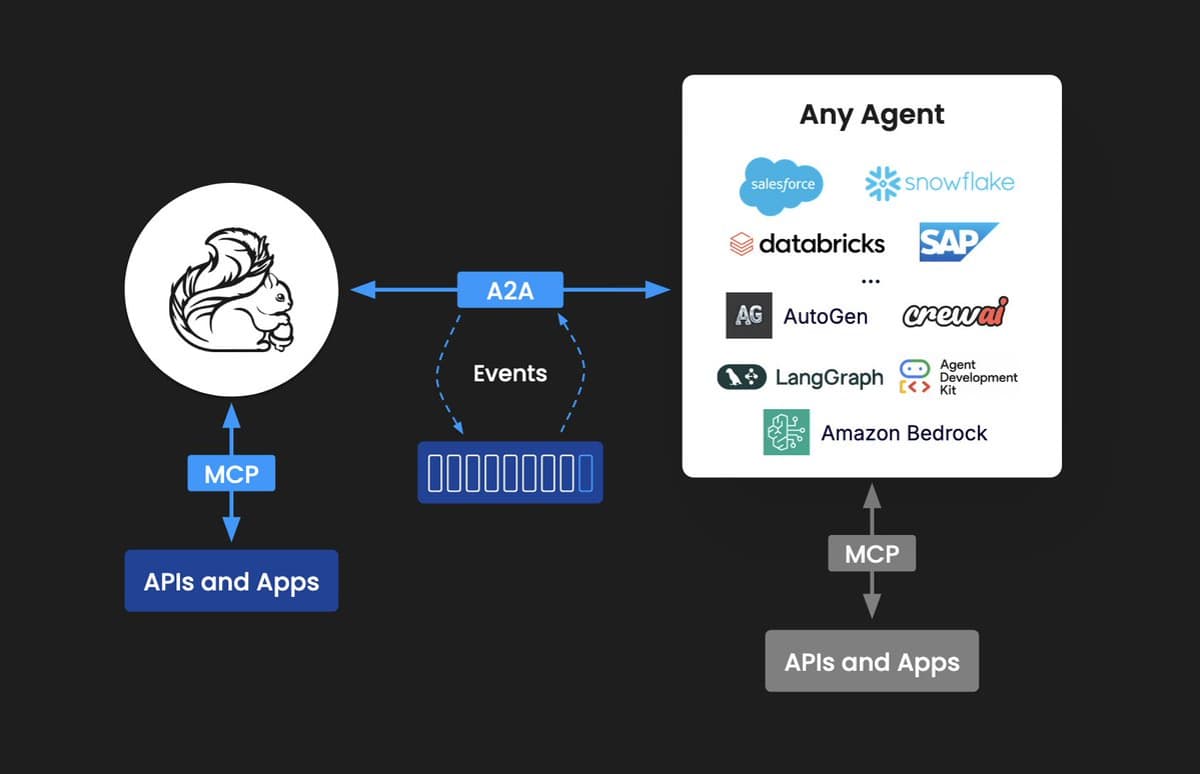
Confluent Adds MCP and A2A Support to Its Platform
Agent standards like MCP and A2A are starting to show up in more types of packaged software. @confluentinc just shipped updates to their data products, including their "intelligence" platform that now supports A2A and MCP integrations. https://t.co/n8teMonFMW https://t.co/1f7afnSw8K

Data Skills, Not AI, Drive Future Business Success
73% of companies are investing more in data and analytics skills right now. Not AI skills. Data skills. Your AI returns depend entirely on your data foundation. The benchmark comparison doesn't change that.

Timescale Beats Clickhouse‑Postgres Combo for Simplicity
Clickhouse is trying to push postgres + clickhouse as the ultimate analytics DB stack. But tbh adding an eventually consistent database to your stack that you needed to sync too is anything but trivial. Love the product but I'd just use...