Today's Big Data Pulse

Leadership Gaps Hamper Data Engineering Teams, Survey Finds
Three 2026 surveys of 1,629 data professionals reveal organizational issues now dominate data‑engineering bottlenecks. In January, weak leadership direction and poor requirements accounted for 40% of top‑bottleneck votes, while by April 50% cited lack of clear ownership as the biggest pain point. Legacy systems and tooling were far lower priorities, at 25% and under 5% respectively.
Also developing:
By the numbers: Sensor Tower acquires AppMagic to expand SMB offering

California Lawmakers Probe Data Center Health and Energy Impacts Amid AI Boom
California legislators have opened a formal inquiry into the health and energy footprints of data centers, citing their rapid growth and projected rise to as much as 12% of national electricity use by 2028. The probe targets exemptions, water‑use reporting and new tariffs on high‑consumption facilities.
Integrating AI-Ready Data with Informatica and Snowflake
Informatica and Snowflake partnered in a DBTA webinar to showcase how metadata‑driven governance, data quality and observability can make Snowflake’s AI Data Cloud AI‑ready. The discussion highlighted Informatica’s end‑to‑end data management capabilities, including tag‑based PII masking, automated semantic classification and...

Guangxi Launches Medical AI Institute to Serve ASEAN, Tapping Vast Clinical Data
Guangxi Medical University inaugurated the Guangxi Medical Artificial Intelligence Research Institute on March 16, positioning the province as a data‑rich gateway for AI‑enabled healthcare in Southeast Asia. The institute will train Chinese algorithms on local disease profiles and ASEAN‑specific data,...

Atomic Transactions in Databricks Spark SQL
Databricks announced that Unity Catalog now supports atomic transactions for managed Delta tables, entering public preview, while Iceberg tables remain in private preview. The feature introduces classic SQL transaction commands—BEGIN TRANSACTION, COMMIT, and ROLLBACK—directly in Spark SQL, extending the platform’s...

Inside OpenAI’s Streaming Backbone with Aravind Suresh | Ep. 24
In this episode, Aravind Suresh, head of OpenAI's real‑time infrastructure team, explains how the company built a highly reliable, scalable streaming backbone for products like ChatGPT using Kafka and Flink. He describes the challenges of scaling a streaming platform tenfold...

#352 AI Agents at Work: What Actually Breaks (and How to Fix It) with Danielle Crop, EVP Digital Strategy &...
In this episode, Danielle Crop, EVP of Digital Strategy & Alliances at WNS, discusses the rapid rise of AI agents in enterprises, emphasizing the need to evaluate whether they deliver real value and operate securely. She advocates a balanced mindset...

Adactin Launches AI-Powered Knowledge Platform AFIVE
Adactin unveiled AFIVE, an AI‑powered knowledge platform built on Microsoft Azure OpenAI and AI Foundry. It uses retrieval‑augmented generation with LangChain to pull data from SharePoint, Google Drive, Azure Blob Storage and Dropbox. The solution offers natural‑language queries, integrates with...

Child Protection Workers Are Under Pressure in NZ. Can Predictive Modelling Help?
Frontline child protection workers in New Zealand face growing caseloads, time pressure and fragmented information, making high‑stakes decisions about child safety and family intervention. Predictive modelling, which analyses large administrative datasets to generate risk scores, has been explored for over a...

Drowning in Data Sets? Here’s How to Cut Them Down to Size
The Square Kilometre Array Observatory (SKAO) will soon produce up to 60 exabytes of raw data annually, dwarfing the 700‑petabyte baseline currently planned for storage. Scientists are forced to discard raw observations once processed images meet quality thresholds, a practice...

Cambridge Memristor Promises Up to 70% Energy Savings for AI Hardware
Researchers at the University of Cambridge have built a synapse‑like memristor that switches at sub‑nanowatt currents and consumes as little as 45 femtojoules per update. The device’s interfacial switching mechanism delivers uniform performance and could reduce AI hardware power draw...

Dirty Data Beats Clean Warehouses in AI Era
For the last couple of decades businesses have been torturing their data into shape so it can earn a seat in a data warehouse. Clean it. Structure it. Label it. Only then does it get invited into the warehouse. And...

ELT Dominates: Load Fast, Transform In‑warehouse Layers
ETL (Extract, Transform, Load): Transform before loading into the warehouse ELT (Extract, Load, Transform): Load first, transform inside the warehouse The shift to ELT happened because cloud warehouses became cheap and powerful enough to do transformations. Why pay for a separate ETL server...

Guangxi Launches Medical AI Institute to Feed ASEAN Health Data Hub
China's Guangxi Medical Artificial Intelligence Research Institute opened in Nanning on March 16, positioning the province as a data‑rich gateway for ASEAN health analytics. The institute will train top‑tier AI models on local disease profiles and roll out multilingual tools...

Built a Month’s Work in Just Two Days
A month of engineering work compressed into 2 days. That's what we shipped for World Sleep Day. We curated a team of 21 agents covering data engineering, biostatistics, public health, visual design, and even data governance and ethics in the...

India Accelerates AI and Big Data Adoption as Public Sector Rolls Out AI Cameras
Snowflake India MD Vijayant Rai says Indian firms are poised for an AI leapfrog, the Ministry of Railways begins installing AI‑powered cameras at New Delhi station, and Anthropic’s global survey of 81,000 users highlights rising expectations and concerns about AI....

DuckDB, AI, and the Future of Data Engineering | with Staff Engineer, Matt Martin
DuckDB is emerging as a mainstream in‑process analytical engine, allowing SQL queries to run directly inside Python, R, or Julia without a separate server. Staff Engineer Matt Martin highlighted how its columnar storage and vectorized execution deliver warehouse‑level performance on...

Pentagon Chooses Palantir AI as Core Military System
Exclusive: Pentagon to adopt Palantir AI as core US military system, memo says. The apotheosis of mil civ fusion... https://t.co/Sp7uxEvsGv

WordPress.com Empowers AI Agents to Write and Manage Site Content Using Analytics
WordPress.com announced that its AI agents—Claude, ChatGPT, OpenClaw and Cursor—can now write, edit and manage content directly on users' sites. The upgrade adds 19 new capabilities across posts, pages, comments, categories, tags and media, leveraging site analytics and theme data...

WordPress.com Empowers AI Agents with 19 New Write Capabilities
WordPress.com announced that its AI agents can now read site analytics and execute 19 new write actions across posts, pages, comments, categories, tags and media. The rollout turns conversational AI into a hands‑on collaborator for thousands of publishers, blending data...

Break Free From ERP: Use Third‑Party BI & AI
Organizations are giving up control by housing data solely within ERP systems. Regain power by leveraging third-party BI, AI, and workflow tools for in-house data management and functionality. #DataControl #ERP #TechStrategy https://t.co/1ForGtniYv

Day 45: Implement a Simple MapReduce Framework for Batch Log Analysis
The post outlines a production‑grade MapReduce framework that handles a full map‑shuffle‑reduce pipeline for batch log analysis, processing millions of events. It features a coordinator‑worker model with automatic task retries and a partitioned storage backend for efficient shuffling. While Kafka...

You Don't Need Permission to Fix Your Data
A junior engineer named Sam quietly added data quality tests to a warehouse model, illustrating that fixing data doesn’t require formal permission. The article argues that data quality problems cost enterprises billions and consume a large share of engineers' time....

Audience Data Shows 86.7% Cross-Platform Affinity Between HBO Max and Paramount+
Parrot Analytics’ latest audience‑behavior charts reveal that HBO Max viewers are 86.7% as likely to watch Paramount+ titles as core Paramount+ users, indicating a highly compatible audience. The data underscores demographic similarity and low friction, bolstering the strategic case for...
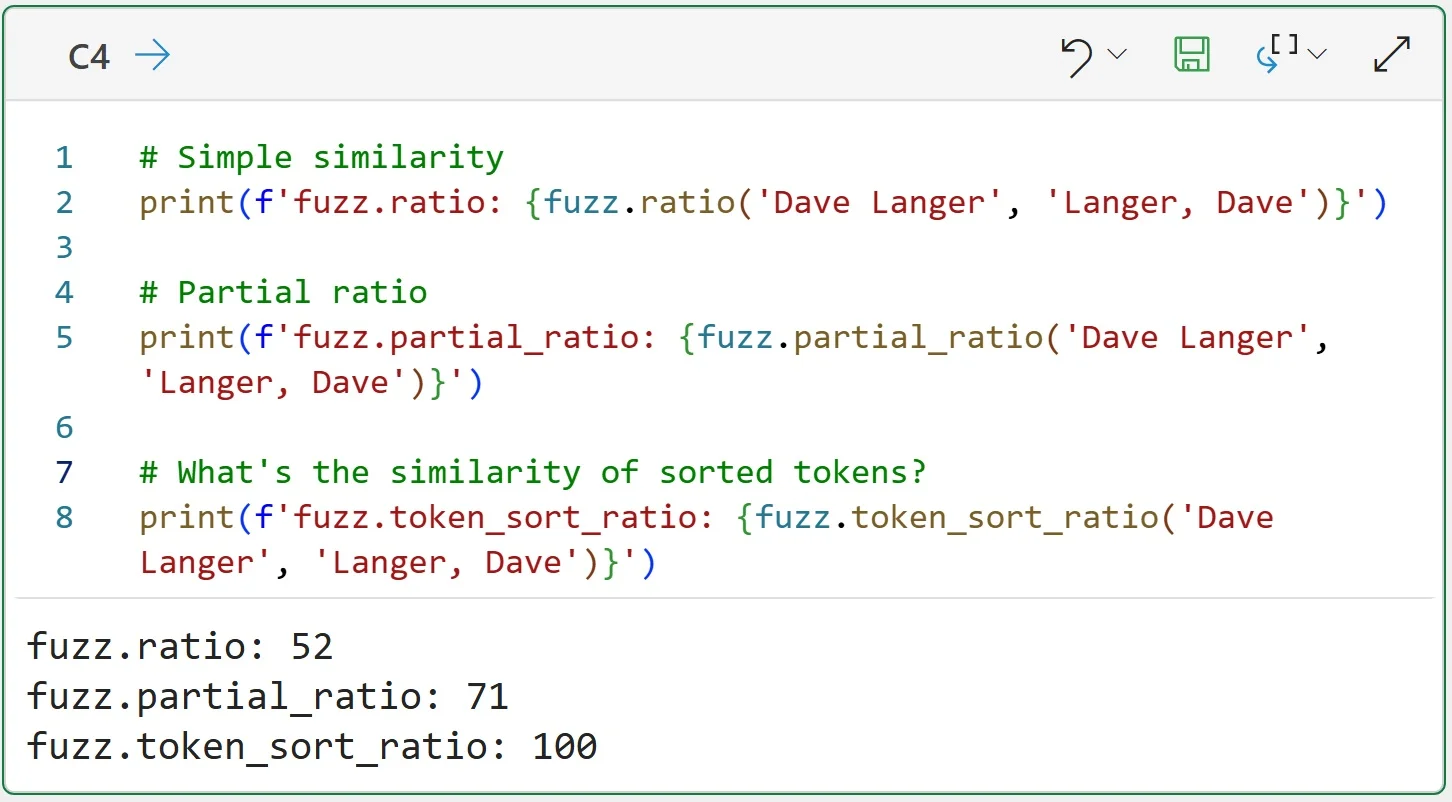
Fuzzy Matching Beats LLMs for Cleaning Text Data
Free-form text data is everywhere in modern organizations. And it's usually dirty. Tomorrow, 39,000+ professionals will learn a powerful way to clean text data - fuzzy matching. In this age of AI, it's tempting to give free-form text data to an...

Accelerating Redshift Modernization with Confidence: How Snowflake Automates and De-Risks Migration
Snowflake’s SnowConvert AI offers an end‑to‑end, AI‑driven solution for migrating Amazon Redshift workloads to Snowflake. It begins with an automated assessment that maps objects, gauges conversion complexity, and creates structured migration waves. The platform then converts SQL and procedural code...

Master SQL Early: It Becomes Your Core Tool
I didn’t prioritize SQL early on, I thought it was easy and not that important. I was wrong. It became the language I used the most in data. Practice your queries.

UBS Upgrade Sends Palantir Shares Soaring on AI‑Data Growth Outlook
UBS analyst Karl Keirstea upgraded Palantir to a buy and raised his price target to $200, implying a 29% upside. The upgrade triggered a strong intraday rally in Palantir shares. Investors are eyeing the company’s 70% YoY revenue growth and...

Toward Intelligent Data Quality in Modern Data Pipelines
Modern data pipelines face growing data quality challenges that go beyond simple schema checks, as subtle semantic drift and incomplete datasets can silently degrade analytics. Current deterministic quality frameworks rely on static rules and thresholds, which become noisy and costly...

AI Fails without Clean, Documented, Owned Data
Most companies experimenting with AI are not struggling with models. They’re struggling with: – messy internal data – inconsistent schemas – no documentation – no data ownership You can’t plug OpenAI into chaos and expect magic. Data hygiene is important for AI.

AI Sparks Data Governance Renaissance, Becomes Business Imperative
.@ActianCorp CEO Potter: AI driving a data governance renaissance https://t.co/4qlBrAGgYY Actian CEO Marc Potter said AI is proving to be a wakeup call on data governance as companies realize it's a business imperative. #AIF2026

Understanding the Layers of the AI‑ready Modern Data Stack
Enterprises are rapidly replacing legacy data architectures with an AI‑ready modern data stack as AI initiatives surge. Deloitte’s 2026 survey shows strategic AI readiness rose to 42%, but confidence in data‑management capabilities slipped to 40%, while an IDC study found...

New Tool Audits Data, Flags Inconsistencies for Equity Quality
You can now audit each number and flag any inconsistencies. We take data quality very seriously. I don't expect you to have to use this, but anything we can do to build the best data set in equity markets, consider it done....

Data Quality Soars 232%, Beating AI Hype
Data quality influence surged 232% this period. Not AI models. Not agents. Not LLMs. Data. Quality. The most boring discipline in the stack just became the fastest growing. The market is telling you something. Are you listening?

Planet Labs Posts 26% Revenue Rise and First Annual EBITDA Profit in Q4 2026
Planet Labs announced $307.7 million total revenue for 2026, a 26% year‑over‑year increase, and $86.8 million in Q4, up 41% YoY. The company posted its first full‑year adjusted EBITDA profit of $15.5 million and generated $52.9 million in free cash flow, driven by expanding...

From DLT to Lakeflow Declarative Pipelines: A Practical Migration Playbook
Databricks is rebranding Delta Live Tables as Lakeflow Spark Declarative Pipelines, adding open‑source Spark alignment and new features. Existing DLT pipelines run unchanged, but Databricks recommends updating imports, decorators, expectations, and CDC logic to the new `dp` API. The migration...

How to Build an Effective Big Data Strategy
Smart organizations leverage big data to boost performance, but without a clear strategy they risk duplicated projects, compliance breaches, and wasted spend. The article outlines a four‑step framework—defining business goals, assessing data readiness, prioritizing use cases, and creating a flexible...

IQIYI Repurchases $207.8 Million of Convertible Notes, Leaves $259 K Outstanding
iQIYI finished a $207.8 million repurchase of its 6.50% convertible senior notes due 2028, leaving only $259,000 of principal outstanding. The move reduces the company's debt load but comes as its shares trade near a 52‑week low and analysts flag a...

LightningChart Introduces No-Code Visualization Platform Dashtera
LightningChart unveiled Dashtera, a no‑code, web‑based analytics platform that leverages GPU‑accelerated rendering to display up to 100 million data points in real time. The solution removes the need for extensive implementation projects, data reduction, or custom integration, delivering instant zoom and...

Informatica Adds Microsoft Fabric Support and Opens Swiss Data Center
Informatica announced general availability of Microsoft Fabric Open Mirroring within its Intelligent Data Management Cloud (IDMC) and launched a new Azure‑based IDMC delivery point in Switzerland. The Open Mirroring feature lets customers synchronize data between OneLake and Fabric Data Warehouse...
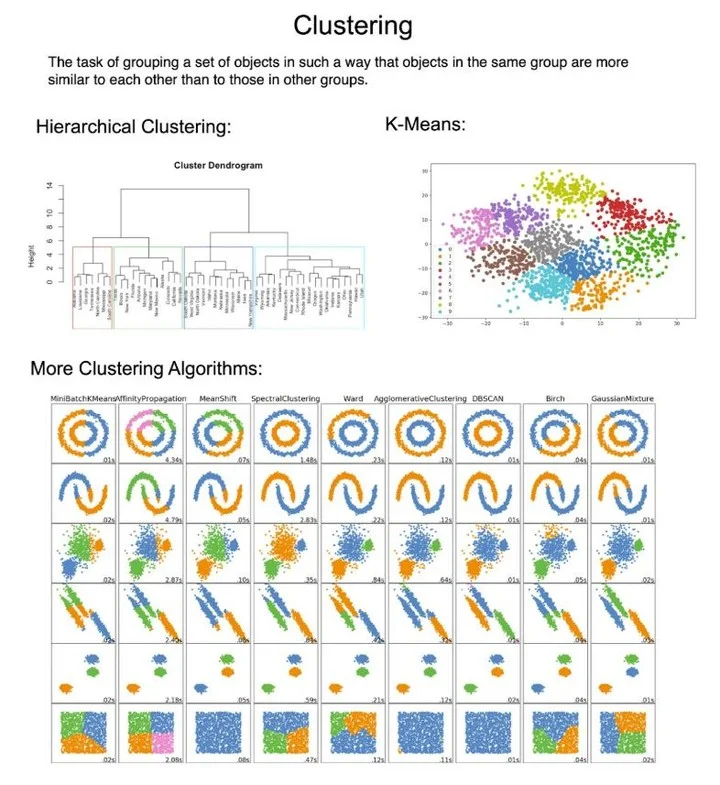
Master the 10 Essential Clustering Techniques
The 10 types of clustering that all data scientists need to know. Let's dive in:

CollectForU Expert and Debt Hunter Reveal 70% of Hong Kong SMEs Lack Credit Defenses
Credit‑management firms CollectForU Expert and Debt Hunter released a joint report on March 16 showing more than 70% of Hong Kong SMEs lack solid credit‑defense mechanisms, leaving them vulnerable to liquidity strain. The study flags the 90‑day delinquency mark as...

Interview: Huy Dao, Director of Data and Machine Learning Platform, Booking.com
Booking.com’s data and machine‑learning platform, led by Huy Dao, has completed a seamless migration from on‑prem Hadoop to a Snowflake‑based cloud ecosystem. The new Booking Data Exchange serves over 1,500 practitioners, handling petabytes of data and billions of daily predictions...

Dagster: Asset‑First Orchestration Over Task‑Centric Pipelines
Dagster has a steep learning curve but a payoff. It is Vim for orchestration. The mental model shift: Dagster thinks in assets, not tasks. You define what data should exist, not what steps to run. The engine figures out dependencies and...

Databricks' Genie Code Automates Data Science and Engineering
I shared my thoughts with @Infoworld on the new Genie Code from @Databricks https://t.co/54nQ6q4vAQ The goal is to highly automate data science and engineering tasks.

SAPinsider Las Vegas: Why Data Strategy Must Start With Trust:
At SAPinsider Las Vegas 2026, Ingo Hilgefort warned that data‑driven AI projects fail when organizations lack trust in their data. He argued that inconsistent definitions and poor governance cause users to rebuild dashboards to verify numbers, stalling analytics adoption. Hilgefort...

How a Nonprofit Transforms Data with Cloudera and AI
Rare Hope, a nonprofit focused on rare‑disease hypotheses, adopted Cloudera’s hybrid data‑and‑AI platform to turn unstructured research papers and medical images into structured insights. Using PySpark pipelines, the organization extracts disease‑drug correlations and feeds them to large language models for...

Federal AI Needs a New Data Foundation. Dell’s Platform Is Built for It.
The federal government is accelerating its adoption of generative AI, retrieval‑augmented generation, and early agentic systems, but agencies are constrained by legacy data architectures. Dell’s AI data platform offers a secure, federated foundation that lets classified and regulated data remain...

Taming the IoT Firehose: How Utilities Are Scaling Cloud DataOps for Smart Metering
Utilities are grappling with an "IoT firehose" as smart meters generate massive, continuous telemetry streams. To tame the volume, they are adopting cloud‑based DataOps frameworks that automate ingestion, normalize data, and deliver analytics‑ready datasets at scale. Automated, event‑driven pipelines enable...

Universal Semantic Layer Needed for Multi-Tool Data Access
The semantic layer isn't new. SAP BusinessObjects had one in 1991. What's new is the need for a universal semantic layer that works across BI tools, notebooks, and applications. When you only had one BI tool, that tool's semantic layer was enough....

Microsoft Promises All-in-One Database Wrangling Hub on Fabric
Microsoft unveiled Database Hub, an early‑access tool built on the Fabric data platform that consolidates management of Azure SQL Server, Cosmos DB, PostgreSQL, MySQL, Azure Arc‑enabled SQL, and other services. The hub offers a single pane of glass for on‑premises,...