Today's Big Data Pulse

Leadership Gaps Hamper Data Engineering Teams, Survey Finds
Three 2026 surveys of 1,629 data professionals reveal organizational issues now dominate data‑engineering bottlenecks. In January, weak leadership direction and poor requirements accounted for 40% of top‑bottleneck votes, while by April 50% cited lack of clear ownership as the biggest pain point. Legacy systems and tooling were far lower priorities, at 25% and under 5% respectively.
Also developing:
By the numbers: Sensor Tower acquires AppMagic to expand SMB offering

Lloyd's Register, OneOcean Report Warns Shipping Must Master Data to Remain Competitive
Lloyd’s Register and OneOcean released a report warning that the maritime sector’s surge in operational data is hampered by fragmentation and low standardisation, jeopardising compliance and commercial advantage. Their Digital Maturity Index shows data standardisation at 2.45 / 4 while overall digital maturity lags at 2.1 / 4, underscoring uneven progress. Regulatory frameworks such as the EU Emissions Trading System and FuelEU Maritime make reliable data essential for emissions reporting and decision‑making. The study highlights that satellite connectivity, cloud platforms, and AI can unlock value, but only with robust data governance and industry collaboration.
Oracle Announced the General Availability of Oracle Analytics Server 2026
Oracle announced the general availability of Oracle Analytics Server 2026, delivering a suite of enhancements aimed at boosting adoption, performance, and governed self‑service. New defaults for the "Limit Values By" filter and a redesigned State menu streamline workbook interactions. The...

DuckDB, AI, and the Future of Data Engineering
In this episode, Dan Beach chats with State Farm staff engineer Matt Martin about his journey from industrial engineering to data engineering, his deep involvement with DuckDB, and the evolving landscape of data platforms. Matt shares how early automation with...
Nvidia GTC 2026: DDN Launches IndustrySync Pipelines for Financial Services and Life Sciences AI
DDN announced IndustrySync Pipelines, pre‑integrated AI data workflows for Financial Services and Life Sciences, deployable on its HyperPOD platform in days instead of months. The Financial Services pipeline promises up to 150× faster risk simulations and five‑minute risk metric refreshes,...

DataOps Engineers: The Underrated Backbone of AI Efficiency
The most underrated AI role right now: DataOps Engineer. Not the ML engineer. Not the data scientist. The person who designs automation and testing infrastructure that makes everyone else dramatically more effective. Infrastructure that runs without you. That's the whole job. https://t.co/Cng5iC1BEB

GHD Appoints David McLaren to Lead Data and AI Capabilities Globally
GHD has appointed David McLaren as its Enterprise Data & AI Leader, based in Toronto. McLaren brings experience from Coca‑Cola Canada Bottling, where he built enterprise‑scale data platforms, automation and governance. At GHD he will steer the development of an...

Nigerian Firms Chase Data Analytics Skills as 8% Revenue Boost Spurs Demand
Nigerian companies are rapidly adopting data analytics, motivated by research showing an average 8% revenue increase for firms that use analytics tools. The shift is creating a talent crunch as businesses, from banks to retailers, scramble to upskill staff and...

Data Lineage Documentation Matters for Enterprise Reliability
Enterprises are increasingly recognizing that knowing where data resides is insufficient without visibility into its lifecycle. Data lineage—tracking origin, transformations, and access—provides the transparency needed for accountability, data quality, compliance, and reduced technical debt. The article highlights how poor lineage...

Ibrar Ahmed: RAG With Transactional Memory and Consistency Guarantees Inside SQL Engines
Current retrieval‑augmented generation (RAG) systems were built for static document search, which creates consistency problems when multiple agents write concurrently. Without transactional control, memory updates can become partially committed, leading to answer drift and silent corruption. The article proposes using...

Nvidia‑Backed Starcloud Seeks FCC Approval for 88,000‑Satellite AI Data Center Constellation
Redmond‑based Starcloud, a Nvidia‑backed startup, filed an FCC application on March 16, 2026 to deploy up to 88,000 low‑Earth‑orbit satellites that would act as orbital data centers for AI workloads. The plan envisions a dusk‑dawn, sun‑synchronous constellation operating between 600...

Nvidia Unveils Groq 3 Inference Chip to Power Multi‑Agent AI at GTC 2026
On March 16, 2026 at its GTC conference in San Jose, Nvidia announced Groq 3, a dedicated inference processor built on technology licensed from Groq Inc. The chip arrives in 256‑LPU LPX server racks with 128 GB of solid‑state RAM and 40 PB/s...

Nvidia Unveils $1 Trillion AI Roadmap, Vera CPUs & BlueField‑4 Storage at GTC 2026
On March 16, 2026, Nvidia CEO Jensen Huang announced at the GTC developer conference in San Jose that the company expects $1 trillion in AI chip orders through 2027, unveiled the Vera Rubin CPU/GPU platform, and introduced the BlueField‑4 STX reference...

IBM Finalizes $10 B Confluent Deal, Making Real‑Time Data Core of Enterprise AI
On March 18, 2026, IBM announced the completion of its $10 billion acquisition of data‑streaming platform Confluent, cementing the deal in the United States. The transaction gives IBM full ownership of Confluent’s Apache‑Kafka‑based technology, which IBM says will become the engine...

Intelligence and Interoperability: Data Catalog Must-Haves for AI Data Governance
Enterprises must move beyond static data catalogs toward a universal AI catalog that combines a business‑friendly semantic layer with cross‑platform interoperability. The semantic layer supplies machine‑readable context, preventing misinterpretations by AI agents, while universal interoperability ensures governance, security, and metadata...
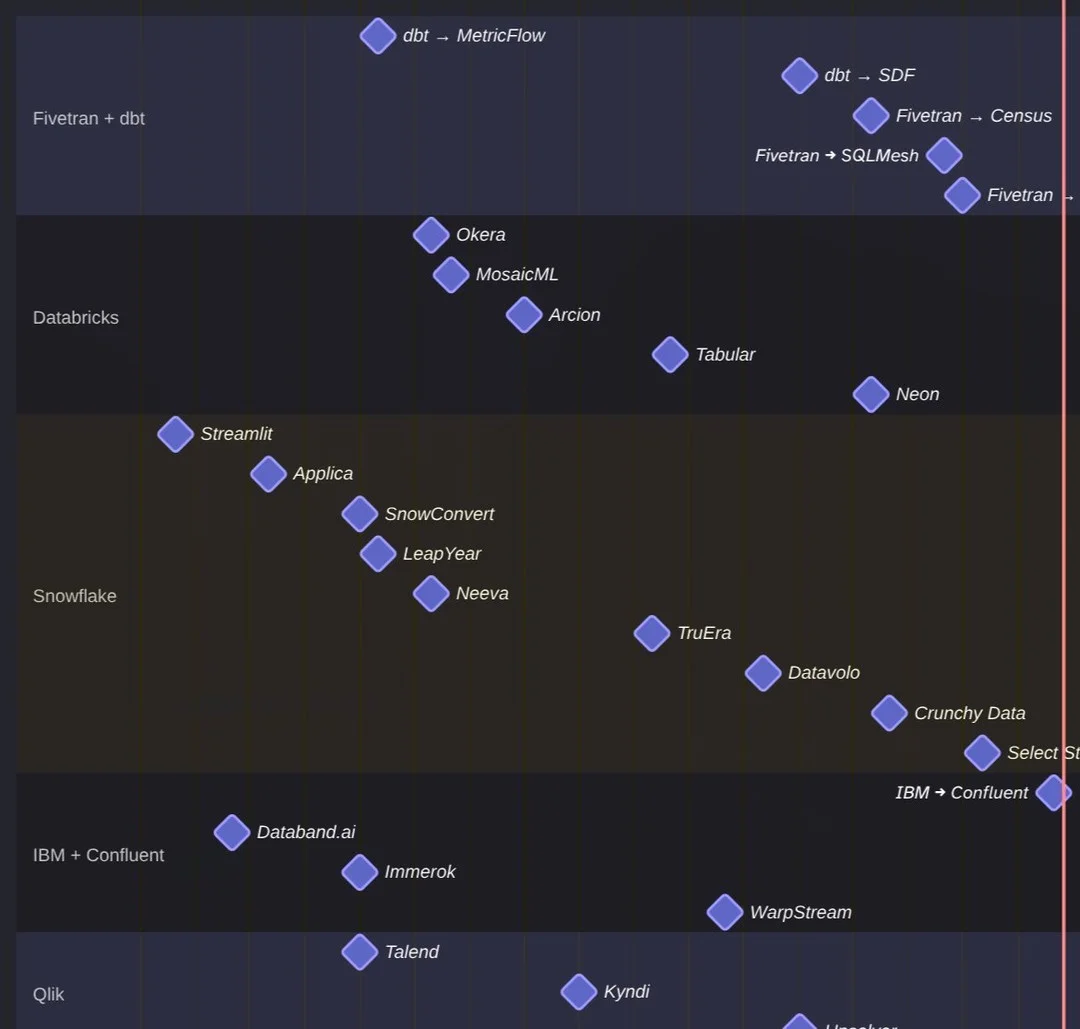
IBM Joins Data Platform Race with Confluent Acquisition
With the latest acquisition of Confluent by IBM, they follow up on the Fivetran, Databricks, and Snowflake stack. Or what do you think? With the latest acquisition in data engineering, it's a race of who gets the most complete data platform...

Orchestration Turns Data Stack Flexibility Into Cohesion
The Modern Data Stack promised best-of-breed tools that work together seamlessly. The paradox: the more tools you pick, the more integration work you create. One perspective I find helpful: Orchestration as the connective tissue. A good orchestrator doesn't just schedule jobs -...

Datadobi Announces Early Access Program for Data Access Review
Datadobi has launched an Early Access Program for Data Access Review, a new permissions‑intelligence capability for its StorageMAP platform. The feature adds visibility into who can access unstructured data, helping organizations spot excessive, outdated, or inappropriate rights. Selected current StorageMAP...

IBM Acquires Confluent to Power Real‑time Enterprise AI
.@IBM Completes Acquisition of Confluent, Making Real Time Data the Engine of Enterprise AI and Agents https://t.co/QqwqJPCT4P >> Congrats. A key augmentation for the IBM AI capabilities. Good news for customers. #NextGenApps https://t.co/aCKH7wuesW

Databricks, Accenture Launch Joint Business Venture Focused On Spurring AI Development
Databricks and Accenture have launched the Accenture Databricks Business Group, a joint venture designed to accelerate enterprise adoption of the Databricks Data Intelligence Platform for AI and data workloads. Backed by more than 25,000 Databricks‑trained professionals, the group will help...

Agentic AI Is Forcing Analytics and Operations to Converge
Investments in data platforms have shifted from siloed warehouses to unified, sovereign foundations as agentic AI collapses analytics, operations, and AI into single workflows. Enterprises now need platforms that govern operational execution, high‑concurrency analytics, and AI reasoning together, rather than...

Better Cotton Funds On-Farm Data-Collecting Project
The Better Cotton Initiative (BCI) is launching a $200,000 on‑farm data‑collection effort in partnership with the Soil Health Institute and ag‑tech provider Growers Guide. The program will analyze soil, plant tissue and sap samples across the Southeast and other Cotton Belt...

Big Changes in Latest GigaOm Unstructured Data Management Radar Report
GigaOm released version 6 of its Unstructured Data Management Radar, expanding the vendor set to 23 and appointing James Brown as the new analyst. The report reclassifies 11 suppliers as leaders and 12 as challengers, with notable moves such as Panzura shifting...

Day 44: Real-Time Monitoring Dashboard with Kafka Streams
The post walks through building a production‑grade real‑time monitoring dashboard that ingests over 40,000 events per second using Kafka Streams. It shows how windowed aggregations, percentile calculations, and anomaly detection run on RocksDB‑backed state stores with exactly‑once guarantees. The stream...

Noémi Ványi: We Skipped the OLAP Stack and Built Our Data Warehouse in Vanilla Postgres
Xata built a product analytics warehouse using vanilla Postgres, consolidating identity, usage, billing, and event data from four separate systems. They employed materialized views, pg_cron schedules, and database branches to flatten JSONB events, refresh data daily, and iterate safely on...

Visualizing the World with Planetary Computer
Microsoft’s Planetary Computer offers a free, standards‑based geospatial data platform that aggregates curated datasets from government, academic and commercial sources. It provides STAC‑compatible APIs, Python and R SDKs, and an Explorer UI for rapid prototyping of environmental applications such as...

Coles Sets up Standard Data Streaming Platform Groupwide
Coles Group has deployed an enterprise‑wide data streaming platform built on Confluent Cloud, unifying its real‑time data pipelines under a single Apache Kafka foundation. Previously, isolated event‑streaming stacks created silos, inconsistent models, and governance challenges. The new "enterprise event platform"...

IBM, Nvidia Tackle AI Data Woes
IBM expanded its partnership with Nvidia at GTC 2026 to address enterprise AI data management challenges. The collaboration integrates Nvidia’s cuDF toolkit with IBM’s Presto query engine and adds Nemotron models to IBM’s Docling PDF reader. Nvidia GPUs will also power...

Free Datasets + LLM Queries on Snowflake, BigQuery
Snowflake and BigQuery have free datasets you can use to practice SQL with real data. Even better: LLMs are integrated, so you can query in natural language.

AI Adoption Demands Stronger, More Responsive Data Foundations
As AI moves to core operations, pressure on the data layer also intensifies. I canvassed leaders on the work required to build a well-functioning data environment responsive to today’s AI initiatives. (My latest in Database Trends) https://t.co/X8ar2pKnTZ @BigDataQtrly

Nvidia Plans to Make All Unstructured Data Structured
Nvidia announced a plan to structure hundreds of zettabytes of unstructured data each year, turning it into the ground‑truth foundation for artificial intelligence. The initiative relies on confidential computing, ensuring that even the platform operator cannot view the raw data....

Online Feature Store for AI and Machine Learning with Apache Kafka and Flink
Wix.com has built a real‑time online feature store using Apache Kafka and Apache Flink to power personalized recommendations for its 200 million users. The architecture streams over 70 billion events per day through 50 000 Kafka topics, with FlinkSQL performing low‑latency transformations and...

BigQuery Studio Gains Context‑Aware Editing and AI Discovery
We just turned on some new smarts in the @googlecloud BigQuery Studio interface. Now you get context-aware query editing (sees open query tabs), better resource discovery through natural language questions, and smarter troubleshooting. https://t.co/9ekJhzv0Ki https://t.co/SNntL6X6bB
Polars Powerful Streaming Engine
Polars’ new streaming engine offers a single‑node, Rust‑based alternative to heavyweight distributed frameworks like Spark. By applying lazy query optimisation and batch‑wise materialisation, it delivers low‑latency ETL pipelines while dramatically cutting hardware costs. Early adopters have swapped Spark jobs for...

The 1 Billion Row Challenge with Gunnar Morling | Ep. 23
In this episode, Tim talks with Gunnar Morling, a principal technologist at Confluent and a key contributor to projects like Hibernate and Debezium, about his "One Billion Row Challenge"—a viral coding contest he launched for the Java community in January...
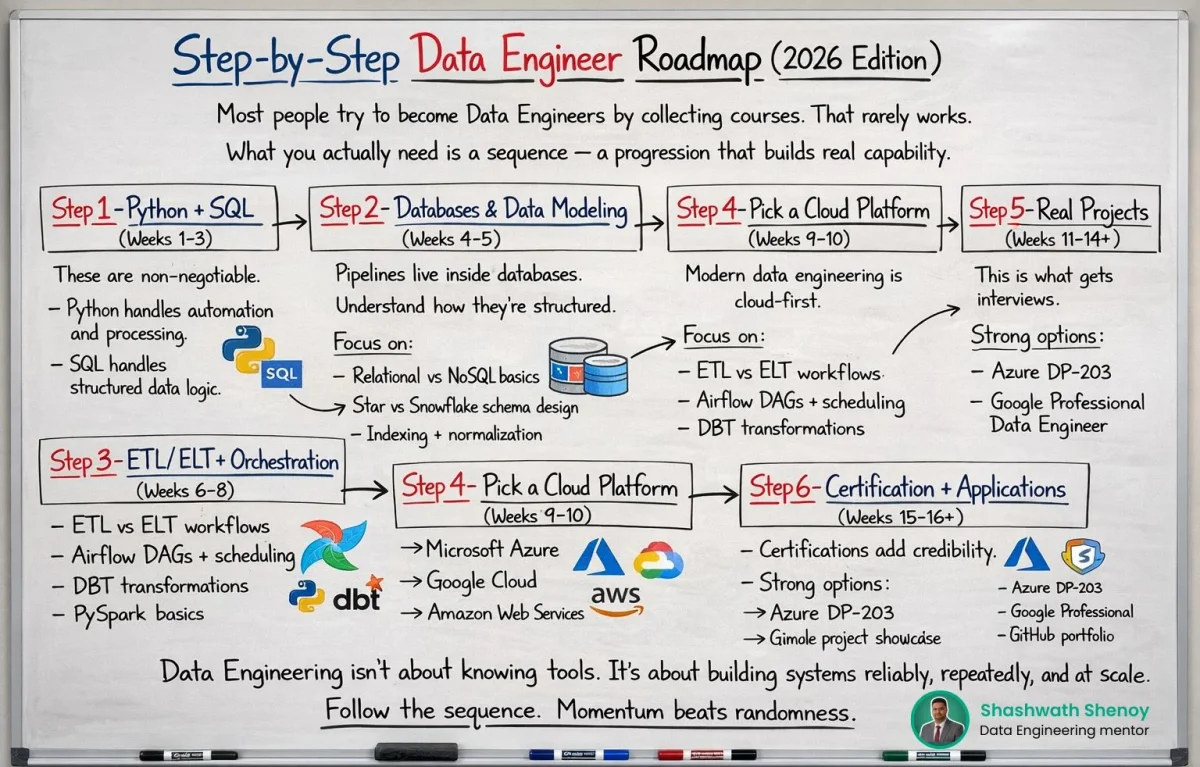
Follow a Structured Roadmap, Not Random Courses, to Engineer Data
𝐒𝐭𝐞𝐩-𝐛𝐲-𝐒𝐭𝐞𝐩 𝐃𝐚𝐭𝐚 𝐄𝐧𝐠𝐢𝐧𝐞𝐞𝐫 𝐑𝐨𝐚𝐝𝐦𝐚𝐩 (2026 𝐄𝐝𝐢𝐭𝐢𝐨𝐧) Most people try to become Data Engineers by collecting courses. That rarely works. What you actually need is a sequence a progression that builds real capability. Here’s a practical 6-stage roadmap that takes you from foundation → job-ready 👇

Pick Data Modeling Pattern Based on Needs, Not One‑Size
I think about data modeling patterns in four main categories: 1. Dimensional modeling (Kimball) - optimized for queries 2. Data Vault - optimized for auditability and change 3. One Big Table - optimized for simplicity 4. Medallion Architecture - optimized for incremental refinement No pattern...
Day 149: Orchestrating Your Log Processing Empire with Kubernetes
The post walks readers through turning a complex, distributed log‑processing stack—collectors, RabbitMQ, query engines, and storage—into a single Kubernetes deployment. By providing complete manifests, it shows how to launch the entire ecosystem with one command, while Kubernetes handles health checks,...

CTEs Turn Complex SQL Into Readable, Maintainable Code
SELECT, FROM, WHERE and JOINs will get you started. Then the work gets complicated and you realise tutorial SQL and production SQL are two very different things. Here's level 2 CTEs — readability I was lost in my own nested subqueries. Couldn't follow...

Understanding and Improving Data Repurposing
The authors introduce data repurposing as the practice of applying existing datasets to tasks that were not envisioned at collection time. They differentiate repurposing from traditional data reuse, emphasizing new analytical goals and contextual shifts. A structured framework is presented,...
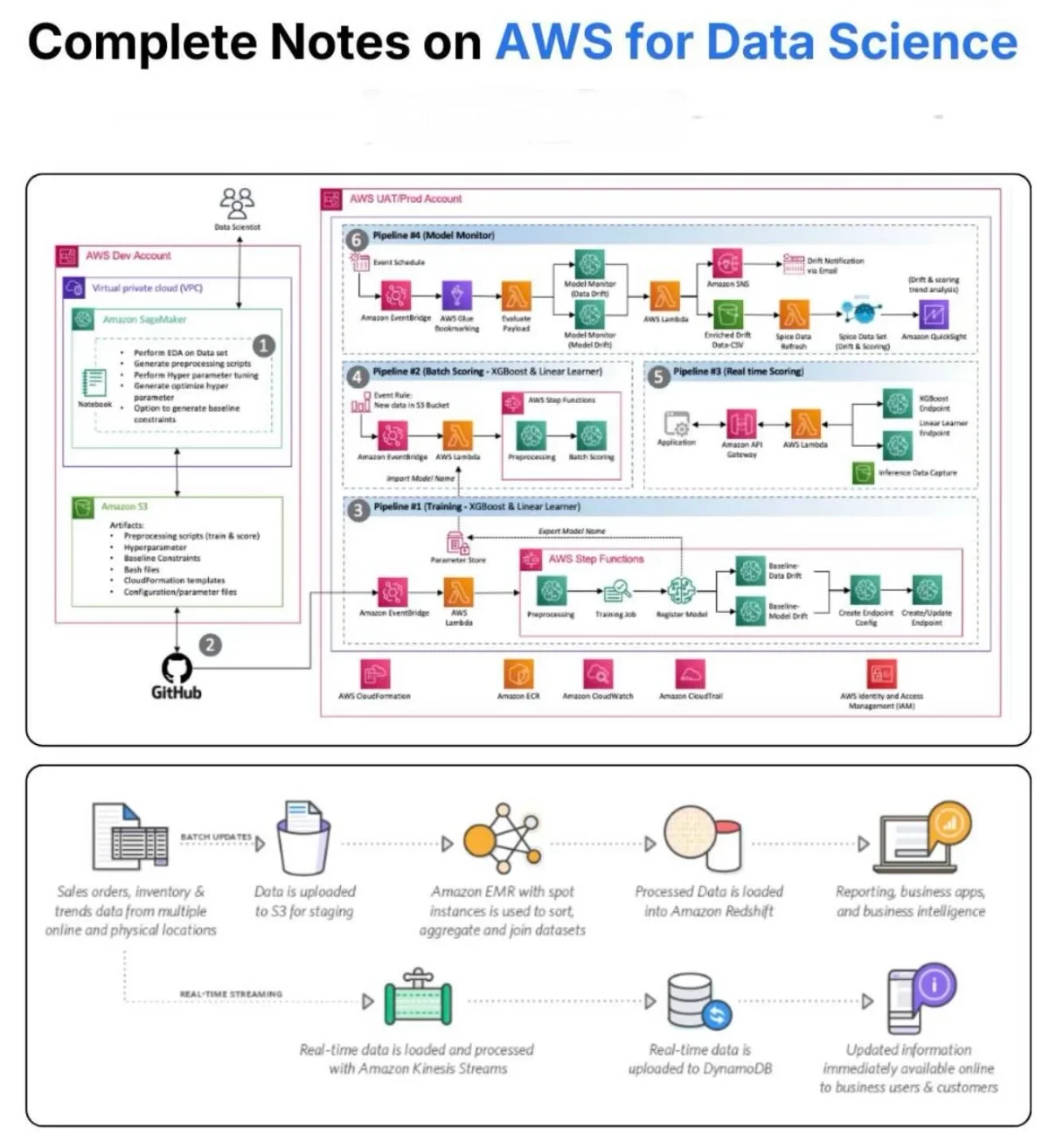
Build End‑to‑End ML with AWS: Glue to SageMaker
A real AWS Data Science pipeline looks like this: Raw data → S3 ETL → AWS Glue Query → Athena Training → SageMaker Deployment → Endpoints Monitoring → CloudWatch Add streaming with Kinesis and orchestration with Step Functions, and you have a full production ML platform. This is...

Generative AI Adds Interpretive Layer to US Strike Planning
Though the US military's big data initiative Maven has sped up the planning of strikes for years, the comments suggest that generative AI is now adding a new interpretative layer to such deliberations.

Digna Reports 12-Month Enterprise Deployment Without Traditional Data Quality Rules
digna announced a twelve‑month enterprise data‑warehouse deployment that operated without any traditional, manually coded data‑quality rules, relying instead on AI‑driven anomaly detection. The platform replaced thousands of null checks, threshold controls, and custom SQL assertions with statistical learning models that...

Effective Data Lineage Connects SQL and Python Pipelines
Data lineage traces your data's journey from source to destination. Where did this number come from? What would break if I changed this table? Who's using this data? Good lineage answers these questions. Bad lineage makes you grep through code. Tools like dbt...

Sema4.ai Announces Semantic Layer Capabilities at the Gartner Data & Analytics Summit 2026
Sema4.ai announced the general availability of its AI‑powered Semantic Layer at the Gartner Data & Analytics Summit 2026. The platform lets business users query databases, spreadsheets and documents using plain English, eliminating the need for SQL expertise. It couples a...

Explore Pipe Syntax in BigQuery Sandbox for Free
Have you tried out pipe syntax instead of traditional SQL? I've only messed around with it a bit. I can see how it's an improvement for different types of queries. This post shows you how to try it out (at no...

Tower Secures €5.5M to Support Data Engineers in the AI Era
Berlin‑based Tower announced a €5.5 million raise across pre‑seed and seed rounds, led by DIG Ventures and Speedinvest. The startup offers a unified storage‑compute platform that lets data engineering teams retain full data ownership while accelerating AI‑driven pipeline development. Leveraging Apache...

Low Data Trust Limits the Value of Analytics and AI
Companies are rapidly expanding analytics and AI capabilities, but a new Info‑Tech Research Group study reveals that low data trust is throttling expected business value. Fragmented ownership, inconsistent validation and reactive cleanup dominate current data practices, leading to underperforming analytics...
Day 43: Implement Log Compaction for State Management
The post outlines a production‑grade state management layer built on Kafka log‑compacted topics, featuring a keyed state producer, a consumer that materializes current snapshots, and a Redis‑backed query API. By retaining only the latest record per entity key, log compaction...

How to Use Sqlpackage to Detect Schema Drift Between Azure SQL Databases
The article demonstrates how to use the sqlpackage command‑line utility to detect schema drift between Azure SQL databases by comparing a DACPAC file against a target database and generating a delta script. It outlines a lightweight, scriptable workflow that avoids...

Responsible AI Starts with Zero‑Trust Data Governance
RT You can't have responsible AI without responsible data. Classify AI data, extend zero trust, encrypt in use, and spell out non-negotiable governance policies from day one. #AISecurity #DataGovernance @Star_CIO https://t.co/aiB5P99ido