
7 XGBoost Tricks for More Accurate Predictive Models
The article outlines seven practical XGBoost tricks that boost predictive accuracy on tabular data. It demonstrates how adjusting learning rate, tree depth, subsampling, regularization, early stopping, hyper‑parameter search, and class weighting can transform a baseline model. Code snippets using the scikit‑learn breast‑cancer dataset illustrate each technique. The author emphasizes systematic experimentation to move from decent to high‑performing ensembles.

FastMCP: The Pythonic Way to Build MCP Servers and Clients
FastMCP is a Python framework that streamlines building Model Context Protocol (MCP) servers and clients using decorator‑based abstractions. It handles JSON‑RPC 2.0 messaging, async execution, and multiple transports such as stdio, HTTP, WebSocket, and SSE, while providing built‑in error handling and...

Epsteinalysis.com
A new platform, Epsteinalysis.com, launched under the alias Axiomofinfinity, offers a searchable database called Epstein Files Explorer containing over one million documents and two million pages released by the DOJ. The site employs spaCy’s named‑entity recognition and similarity clustering to...
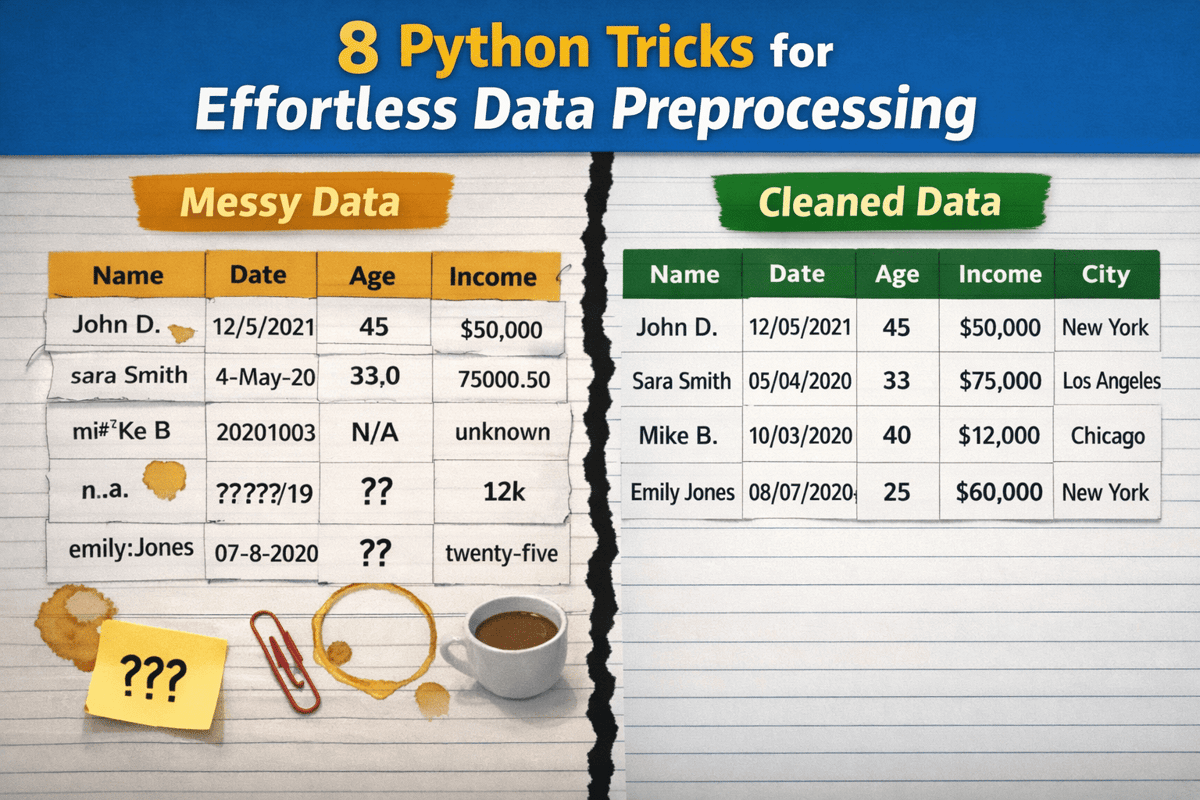
From Messy to Clean: 8 Python Tricks for Effortless Data Preprocessing
The article outlines eight concise Python tricks that streamline data preprocessing, from normalizing column names to clipping outliers. Each technique uses pandas functions to handle whitespace, type conversion, date parsing, missing values, categorical standardization, duplicate removal, and quantile‑based capping. The...

Temporary Tables in Databricks SQL | Do You Actually Need Them?
The article reviews temporary tables in Databricks SQL, explaining how they store intermediate results for the duration of a session and can be referenced across multiple statements. It compares them to Common Table Expressions, highlighting performance gains when avoiding repeated...

Data Governance Without the Jargon: 30 Questions and Answers to Clarify Terms and Trends
Data governance has morphed into a catch‑all term covering quality, metadata, privacy, compliance, and digital strategy, creating ambiguity that blurs responsibilities and stalls decisions. A new resource, "What Is Data Governance? 30 Questions and Answers," builds on the Broadband Commission’s Data...

Hotel BI vs Excel: The Hidden Costs
Excel remains a default tool in hotels, but its apparent zero‑cost facade hides substantial operational expenses. Hotels can spend up to 125 hours each month cleaning, formatting, and moving data, turning revenue managers into data clerks. This manual burden erodes...

All About Feature Stores
Feature stores have moved from niche tools to core infrastructure for operational machine‑learning, providing a single source of truth for features used in both training and online inference. The concept was coined by Uber in 2017 and commercialized by Tecton...

The Data Checkup: A Framework for Assessing the Health of Federal Datasets
The Data Checkup framework, launched by dataindex.us, offers a systematic way to evaluate the health of federal datasets across six risk dimensions. It moves beyond simple URL monitoring to assess historical and future availability, quality, statutory context, staffing, funding, and...

Breaking the Silos: The Rise of the Open Lakehouse Architecture in 2026
In 2026 the open lakehouse has become the de‑facto enterprise data strategy, merging low‑cost data‑lake storage with warehouse‑grade ACID transactions via open standards. By adding a metadata and transactional layer atop object storage, organizations achieve a single source of truth...

The $800B Open Secret: What the New Medicaid Spending Dataset Means for Health Tech Builders and Investors
The episode breaks down the release of the largest publicly available Medicaid claims dataset, detailing its composition, gaps, and immediate utility for health‑tech builders and investors. It quantifies the scale of Medicaid spending (~$849 B) and improper payments (over $30 B annually),...

Migrating to Databricks – A Guide
The guide cautions that moving to Databricks won’t fix weak data fundamentals; organizations must first establish clear dev‑prod separation, version‑controlled code, and cost accountability. It urges teams to define real needs, avoid over‑architecting, and split infrastructure choices from data‑architecture decisions....

Why Declarative (Lakeflow) Pipelines Are the Future of Spark
Spark is evolving from low‑level RDD and notebook‑driven workflows to declarative pipelines, branded as Lakeflow on Databricks. The new framework lets engineers define flows, datasets, and pipelines in a configuration‑first manner, while Spark handles execution for both batch and streaming....

Robin Moffatt on the Evolution of Data Engineering: From Batch Jobs to Real-Time | Podcast Interview
Robin Moffatt discusses how data engineering has shifted from traditional batch processing to real‑time streaming in a recent podcast interview. He outlines the technical drivers—cloud scalability, event‑driven architectures, and low‑latency analytics—that enable continuous data pipelines. Moffatt also highlights emerging tools...

Versioning and Testing Data Solutions: Applying CI and Unit Tests on Interview-Style Queries
The article walks through solving a Tesla interview question in Python, calculating each car maker’s net product launch change between 2019 and 2020 using pandas. It then refactors the script into a reusable function and adds a unit‑test suite to...

Untitled
Ré Dubhthaigh of Dublin City Council highlights that place data is far more complex than simple addresses, encompassing centuries of urban growth. The council must navigate 800+ years of layered, messy data while delivering real services, not starting from a...

Why Coinbase and Pinterest Chose StarRocks: Lakehouse-Native Design and Fast Joins at Terabyte Scale
StarRocks is attracting heavyweight users such as Coinbase, Pinterest and Fresha because it delivers sub‑second query latency on terabyte‑scale analytics while reading directly from lakehouse storage. The platform’s shared‑nothing architecture, colocated joins, caching layer and a cost‑based optimizer let it...

Healing Tables: When Day-by-Day Backfills Become a Slow-Motion Disaster
A data engineering team discovered that a three‑year SCD Type 2 backfill executed day‑by‑day produced 47,000 overlapping records, timeline gaps, and unrecoverable errors. The author introduced "Healing Tables," a framework that separates change detection from period construction and rebuilds the dimension in...

When Data Moves, Risk Moves with It: The Hidden Challenges of Warehousing Data
The episode explores how moving data into modern warehouses and lakes introduces hidden risks that go beyond technical challenges, emphasizing governance, data quality, and transformation controls. It highlights that inconsistencies in source systems, ambiguous definitions, and poorly documented transformation logic...

Is Your Machine Learning Pipeline as Efficient as It Could Be?
Machine learning teams are increasingly overlooking pipeline efficiency, a hidden driver of productivity. Slow data I/O, redundant preprocessing, and mismatched compute inflate the iteration gap, limiting the number of hypotheses tested per week. The article outlines five audit areas—data ingestion,...

5 Open Source Image Editing AI Models
A new KDnuggets article spotlights five open‑source AI models that enable text‑driven image editing, ranging from Black Forest Labs' FLUX.2 [klein] 9B to Alibaba Cloud's Qwen‑Image‑Edit‑2511 and newer adapters like FLUX.2 [dev] Turbo. The models deliver real‑time generation, multi‑reference editing, bilingual support,...

The Lakehouse Architecture | Multimodal Data, Delta Lake, and Data Engineering with R. Tyler Croy
The article introduces the lakehouse architecture as a unified platform that combines the scalability of data lakes with the performance of data warehouses. It highlights how Delta Lake brings ACID transaction support and schema enforcement to open‑source storage, enabling reliable...

Converting Floats to Strings Quickly
Converting binary floating‑point numbers to decimal strings is a core step in JSON, CSV, and logging pipelines. Recent research benchmarks modern algorithms—Dragonbox, Schubfach, and Ryū—showing they are roughly ten times faster than the original Dragon4 from 1990. The study finds...
Data Engineering Career Path: From Circuits to Pipelines
The article maps a data‑engineering career trajectory that begins with hardware‑oriented roles and ends in building scalable data pipelines. It highlights how circuit‑design thinking translates into logical data modeling, while emphasizing the need to acquire SQL, Python, and cloud‑native tools....

Apache Airflow vs Databricks Lakeflow | The Orchestration Battle
The article pits Apache Airflow, the open‑source workflow orchestrator, against Databricks Lakeflow, a newer Lakehouse‑native pipeline engine. It outlines core differences in architecture, integration depth with cloud data platforms, and pricing models. Airflow remains favored for heterogeneous environments, while Lakeflow...

This One Polars Pattern Makes Code 10x Cleaner
The article highlights a single Polars pattern—using the pipe operator—to streamline data‑frame code, cutting boilerplate and boosting readability up to tenfold. By chaining transformations in a lazy execution graph, developers avoid intermediate variables and gain clearer, more maintainable pipelines. The...

I Stress-Tested Cube's New AI Analytics Agent
In this episode, host Joe Reis shares his hobby of stress‑testing AI analytics agents and introduces his own testing framework. He evaluates Cube's new AI analytics agent, highlighting how its semantic‑layer approach prevents common failures like hallucinated tables and incorrect...
New Study Identifies the Top Internal Audit Priorities for 2026
The episode highlights Gartner's new survey of 119 chief audit executives (CAEs), revealing that building a culture of innovation and leveraging data analytics and generative AI are the top internal audit priorities for 2026. While 83% of audit functions are...

Data Contracts: A Missed Opportunity
The episode examines why the data‑industry’s discussion of data contracts stalled at theory rather than implementation, contrasting it with the software world’s shift toward spec‑driven development where specifications become the system itself. It argues that data contracts should be treated...

Apache Arrow ADBC Database Drivers
Apache Arrow’s ADBC (Arrow Database Connectivity) introduces a modern, columnar‑native driver that can replace or complement traditional ODBC/JDBC stacks. By moving Arrow RecordBatches end‑to‑end, it eliminates row‑by‑row marshaling and dramatically reduces serialization overhead. Benchmarks show Python ADBC achieving roughly 275 k...

Xero’s Jolly on Building a Tech Roadmap to Level Playing Field for Small Businesses
Xero has launched an AI‑powered analytics suite aimed at small‑business owners, a move driven by chief product and technology officer Diya Jolly. After acquiring Syft and Melio, Xero now offers customizable dashboards, cash‑flow managers, health scorecards and instant AI‑generated insights....