
Pod Requests Are the Input to Every Kubernetes Cost Control Loop
In Kubernetes clusters, pod resource requests are the primary input for multiple control loops, including scheduling, cluster autoscaling, and pod autoscaling. When requests are inflated, stale, or omitted, the platform over‑provisions capacity, leading to wasted spend and performance degradation. The article advocates treating request sizing as a continuous rightsizing loop rather than a one‑off cleanup, with explicit GitOps ownership and clear overhead modeling to improve cost allocation. Implementing these practices can quickly reveal mismatches between allocated and actual usage in high‑spend namespaces.

Day 44: Real-Time Monitoring Dashboard with Kafka Streams
The post walks through building a production‑grade real‑time monitoring dashboard that ingests over 40,000 events per second using Kafka Streams. It shows how windowed aggregations, percentile calculations, and anomaly detection run on RocksDB‑backed state stores with exactly‑once guarantees. The stream...

The Evolution of Chaos Engineering: From Chaos Monkey at Netflix to Reliability Management in the AI Era
Chaos engineering began with fault‑injection tools at Amazon and Netflix’s open‑source Chaos Monkey, evolving into hypothesis‑driven experiments. Gremlin, launched in 2016, packaged safety controls, methodology, and CI/CD integrations to make the practice scalable across organizations. The approach now includes automated...

GenAI-Based Development Platform - Part 2: How Idea to Code Turns an Idea Into Working, Tested Software
The article details the "i2code implement" subcommand, which orchestrates Claude Code to turn a structured plan into a production‑ready pull request using test‑driven development. It combines deterministic Python setup with AI‑driven code generation, handling setup, recovery, and a repeatable implementation...

8 Best Machine Learning Tools in 2026: What I Recommend
The article ranks the eight top machine‑learning platforms for 2026, highlighting Google Vertex AI, IBM watsonx.ai, SAS Viya, Azure OpenAI Service, Dataiku, Amazon Personalize, Python’s ecosystem, and B2Metric. It bases the selection on G2’s Winter 2026 Grid® data, user reviews, and a criteria set that includes lifecycle...

Meta Renewing Investment Into The Jemalloc Memory Allocator
Meta has announced a renewed commitment to the jemalloc memory allocator, a component it has used for nearly two decades across its infrastructure. The company plans to modernize the codebase, reduce technical debt, and enhance features such as the hugepage...

Generate a No-Cost VMware Migration-Readiness Report with the OpenShift Migration Advisor
The OpenShift migration advisor is a free, self‑service tool that evaluates VMware workloads for migration to Red Hat OpenShift. It connects to a vCenter environment via an RVTools inventory file or an OVA agent and produces a detailed report covering...

The Invisible Rewrite: Modernizing the Kubernetes Image Promoter
The Kubernetes image promoter (kpromo) was completely rewritten, shedding about 20% of its code and adopting a modular, seven‑phase pipeline. The nine‑step effort introduced adaptive rate limiting, clean interfaces, a dedicated pipeline engine, and native SLSA provenance, vulnerability scanning, and...

The Hidden Reliability Risks in Your Agentic AI Workflows
Artificial intelligence has moved from conversational assistants to autonomous agents that act on behalf of enterprises, introducing new reliability challenges. The article highlights three primary risks: unstable network connections, cascading dependency failures, and the non‑deterministic nature of model outputs. It...

Introducing OpenShift Service Mesh 3.3 with Post-Quantum Cryptography
OpenShift Service Mesh 3.3 is now generally available, built on Istio 1.28 and Kiali 2.22, and runs on OpenShift Container Platform 4.18+. The release adds post‑quantum cryptography support with the hybrid X25519MLKEM768 key exchange, expands ambient mode with multicluster technology preview and FIPS...

From Infrastructure Validation to Market Validation: Rafay and NVIDIA DSX Air
NVIDIA DSX Air provides a full‑stack simulation that lets cloud providers validate networking, GPU servers, storage and connectivity before any rack is shipped. Rafay layers a self‑service orchestration platform on top, enabling multi‑tenant, governance and workflow testing alongside the hardware...

Quickly Go From Exploration to Action with New One-Click Integrations in Grafana Drilldown
Grafana has introduced one‑click integrations for its Drilldown apps, enabling users to add panels to dashboards, create alerts, and save searches without leaving the exploration view. The updates also bring an enhanced OpenTelemetry log display that surfaces key metadata inline,...

Best First DevOps Tool for Beginners
Which tool is best for beginners starting DevOps? 👇 1️⃣ Docker 2️⃣ Linux 3️⃣ Git & GitHub 4️⃣ Kubernetes

Vite Team Boasts 10-30x Faster Builds with Rust-Powered Rolldown
Vite 8.0 replaces esbuild and Rollup with Rust‑built Rolldown, delivering 10‑30× faster builds while keeping the familiar plugin API. Rolldown, built atop the Oxc Rust library, is still in release‑candidate status, with minification in alpha. The new version is already...

Google Engineers Reveal AI's Real Impact on Delivery
Perk up when the DORA team does research into software delivery. The surveyed Google engineers to understand how AI tools impacted their work, and where they struggled. The advice is very actionable. https://t.co/PnaUMyiBLp https://t.co/mgU4WJb8SL

Semaphore’s New Pricing Model: Built for the AI Era of CICD
In this episode, Pete Milorovic announces Semaphore's new pricing model tailored for the AI-driven, always‑on CI/CD era. The plan separates compute costs from support and success services, lowers per‑minute rates for high‑performance F1 machines to $0.0075, and shifts self‑agent billing...

LLMs Turn Server Admin Chores Into Planning Time
As someone who has burned more hours than he wants to think on server administration, a *lot* of the cruft of it gets transformatively easier with LLMs, and in lieu of an hour doing deferred maintenance you can spend an...

How Multimodal AI Is Reshaping Kubernetes Workflows: Future-Proofing Your Platform
Multimodal AI workloads—combining text, images, audio, and video—are outpacing traditional AI in complexity, requiring heterogeneous accelerators, bursty scaling, and stateful pipelines. Kubernetes, equipped with GPU operators, MIG slicing, and advanced schedulers like Volcano and KubeRay, provides the core primitives to...

KiloClaw Updates: Persistent Packages, Browser Support, and Connected Accounts
KiloClaw released a suite of March updates that make agents more durable and connected. Users can now link Google and GitHub accounts directly, while package installations via pip, uv, and npm persist across restarts. The default image now includes a...
![What Is Salesforce DevOps [Streamline Development and Deployment in the Cloud]](https://hixhlmpcokxhartfkpyi.supabase.co/storage/v1/object/public/images/thumbnails/ee8ce35dde96030770002acfb9b237f2.webp)
What Is Salesforce DevOps [Streamline Development and Deployment in the Cloud]
Salesforce DevOps merges development and operations practices to accelerate the delivery of customizations, code, and integrations on the Salesforce platform. By adopting source‑driven development, version control, and automated pipelines, teams move away from ad‑hoc production changes toward repeatable, test‑driven releases....

Getting Network Automation Right: A Practical Strategy for Enterprise Networks
Enterprise network automation hinges on strategic planning rather than just tool selection. Leaders must prioritize process maturity, governance, and skill development before deploying IaC platforms like Terraform or Ansible. A phased, high‑frequency task approach mitigates risk in brownfield environments, while...
.png)
The Agent-Native Repo: Why AGENTS.MD Is the New Standard
The article introduces AGENTS.md as a standardized, tool‑agnostic instruction file that makes code repositories agent‑native. It argues that AI coding agents fail mainly due to ambiguous repository context, not reasoning limits, and that a dedicated AGENTS.md layer solves fragmentation across...

Bringing Nemotron Models to the Red Hat AI Factory with NVIDIA
Red Hat announced Day 0 support for NVIDIA’s Nemotron open‑model family, including Nemotron 3 Super, within its AI Factory platform. The integration delivers fully optimized, open‑source generative AI that runs on Red Hat AI Enterprise at the moment of model release. Red Hat will provide...

Betterleaks, a New Open-Source Secrets Scanner to Replace Gitleaks
Betterleaks, an open‑source secrets scanner created by the original Gitleaks author, aims to supersede Gitleaks with a faster, more accurate engine. It scans directories, files, and Git repositories using customizable CEL rules and BPE tokenization, achieving 98.6% recall on the...

GenAI Bridges Divergent Multicloud APIs, IAM, Pricing
RT Multicloud != "just more clouds." It's divergent APIs, IAM models, pricing, and PaaS semantics across AWS, Azure, GCP, Oracle, and others. GenAI introduces a translation layer for configs, code, and policies. #MultiCloud @Star_CIO https://t.co/vBzM21vM14

SLIs, SLOs, and SLAs: How to Measure and Enforce System Reliability
System reliability engineering addresses hardware degradation, software bugs, and network partitions that can trigger cascading outages. The article distinguishes reliability from mere availability and stresses the need to eliminate single points of failure. It introduces Service Level Indicators, Objectives, and...
Day 149: Orchestrating Your Log Processing Empire with Kubernetes
The post walks readers through turning a complex, distributed log‑processing stack—collectors, RabbitMQ, query engines, and storage—into a single Kubernetes deployment. By providing complete manifests, it shows how to launch the entire ecosystem with one command, while Kubernetes handles health checks,...
Preventing Cascading Failures: How to Decouple Microservices with Async Design
Modern microservice architectures often suffer cascading failures when a single downstream component slows or crashes, causing synchronous calls to block threads and exhaust memory. The blog explains how synchronous communication forces services to wait for network responses, leading to system-wide...

Missing MCP Safeguards Turns Experiments Into Production Vulnerabilities
If your MCP server doesn't enforce data scopes, PII controls, and environment isolation, you're not "experimenting with agents" - you're opening side doors into production. #AI #DevOps #MCP https://t.co/7dcoLIKa0K
Kafka Vs. RabbitMQ: How to Choose the Right Message Queue for Your Microservices
Modern microservices rely on asynchronous messaging to avoid cascading failures. The article contrasts Kafka and RabbitMQ, outlining each broker’s architecture, delivery guarantees, and typical use cases. RabbitMQ is described as a smart‑broker with a push model and fine‑grained routing, while...

Troubleshooting Guide: Running Qwen3.5-35B with Reasoning & Tool Calling Using vLLM on Nvidia DGX Spark
The post details how to run the Qwen3.5-35B MOE model—featuring 35 B parameters, 4‑bit AWQ quantization, and a 131 K context window—on Nvidia DGX Spark using vLLM. Standard vLLM Docker images (e.g., nvcr.io/nvidia/vllm:26.01-py3) ship with Transformers versions that do not recognize the...
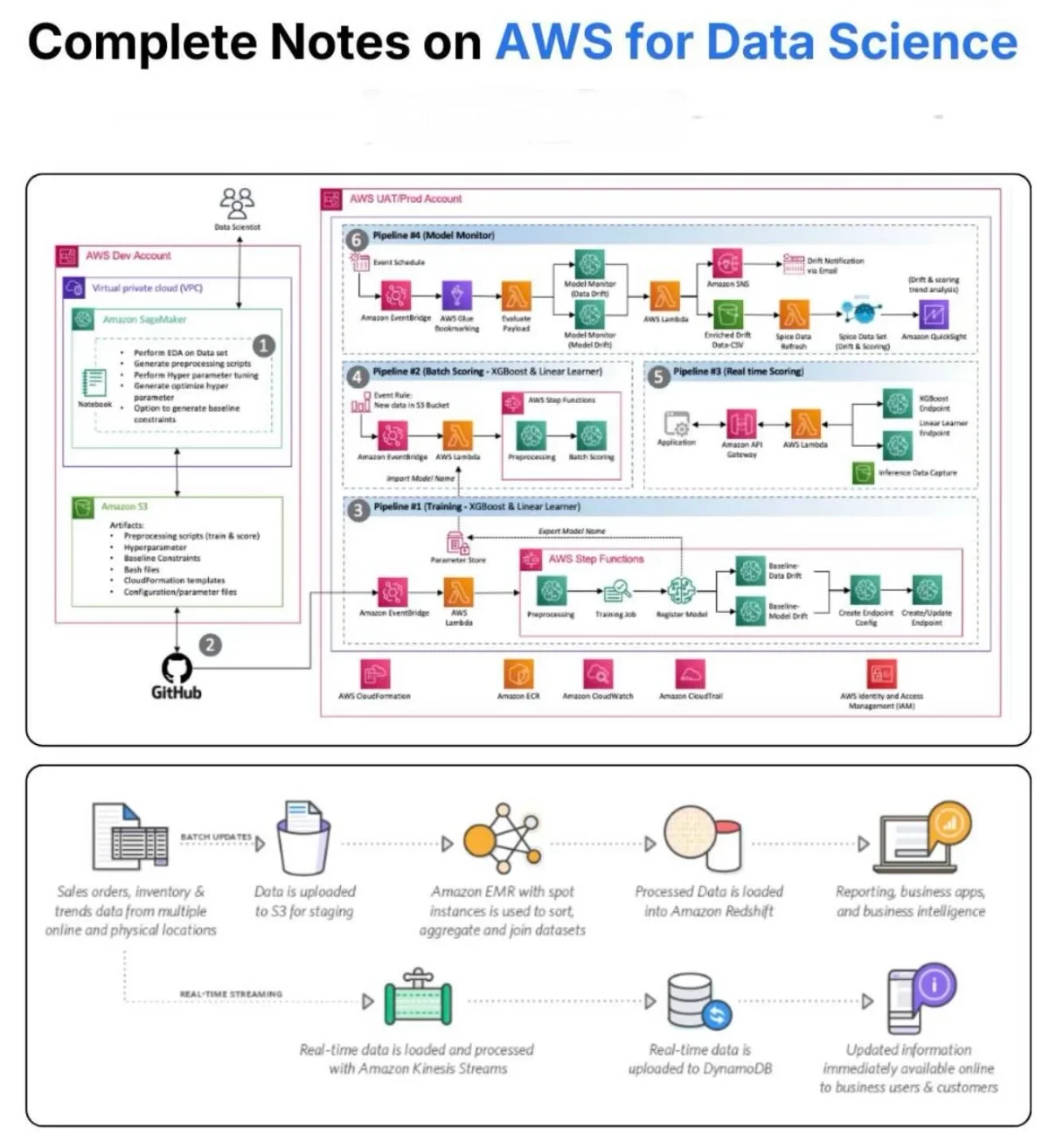
Build End‑to‑End ML with AWS: Glue to SageMaker
A real AWS Data Science pipeline looks like this: Raw data → S3 ETL → AWS Glue Query → Athena Training → SageMaker Deployment → Endpoints Monitoring → CloudWatch Add streaming with Kinesis and orchestration with Step Functions, and you have a full production ML platform. This is...

Google Now Using AutoFDO To Enhance Android's Linux Kernel Performance
Google’s Android LLVM toolchain team announced that it has started using AutoFDO, an automatic feedback‑directed optimization technique, for building the Linux kernel in Android. By incorporating real‑world profiling data, the compiler can generate more efficient kernel binaries. Early measurements on...

How to Debug AI Backend Systems
The article recounts a three‑day debugging nightmare caused by a faulty document‑chunking strategy in an AI Retrieval‑Augmented Generation (RAG) pipeline, highlighting how traditional logging failed to surface the issue. It argues that AI systems require a dedicated observability stack—structured logging,...

Built Automated Batch Job Framework in Two Weeks
If you followed my journey to try to build a batch job framework (below) for like three years well, here’s what I got done vibe coding 🤖 as a chaperone for naughty AI agents and chatbots in two weeks. To...

Debauit Announced As Debian Source Package Auditor
Debaudit, a new suite of verification tools, was announced to audit Debian source packages. It includes upstream2orig, git2dsc, and git2orig, each checking different stages of the source‑to‑binary pipeline. The tools confirm that upstream tarballs, Git repositories, and generated originals match...

March Patches for Azure DevOps Server
Microsoft has released Patch 2 for Azure DevOps Server on March 13 2026, addressing a defect that could deactivate group memberships. The update applies to on‑premises installations that were deployed before the re‑published release and completes remediation for customers who previously ran the...

#540: Modern Python Monorepo with Uv and Prek
In this episode, host Michael Kennedy talks with Apache Airflow core contributors Yarek Patuk and Amag Desai about how they manage one of the world’s largest Python monorepos—over a million lines of code and 100+ sub‑packages—using modern tooling like UV,...

Automate Ticket Ops: Empower Developers with Platform Tools
Have you ever worked in a company where developers get stucked in “ticket ops” this is meant for platform engineers, where developers need the manual approvals as a platform engineer you will be tasked to develop a system or product...

From Signals to Savings: Optimizing Cloud Costs with Grafana Assistant and MCP Servers
Grafana Assistant, an AI agent built into Grafana Cloud, now automates cloud cost optimization by translating natural‑language prompts into telemetry queries. It delivers 30‑day waste analyses, actionable recommendations, and transparent data without requiring PromQL expertise. Integrated with Model Context Protocol...

How to Customize PagerDuty Custom Details in Grafana: The Hidden Override Method
Grafana’s native PagerDuty integration dumps every alert label and annotation into the incident details, creating unreadable payloads. By adding a custom key named "firing" in the contact point’s Details section, users can override the default template and send only essential...

Deploying Models Beats Training for Real Impact
Deploying a model is harder than training it. 🚀 Here’s a simple ML → Production pipeline on AWS: Train model → Build API → Dockerize → Push to ECR → Deploy with Lambda → Serve predictions. Notebook models don’t create impact. Production models do.

Semantic Layer Gives Agents Backend Context, Free Open‑source
Agents fail at backends because they lack context. @insforge_dev V2 fixes this via a semantic layer & MCP 👀 → Connects Claude/Cursor directly to your backend → Auto-configs Postgres DBs, Auth, & S3 Storage → Deploys edge functions seamlessly Free and open-source 🧵↓ https://t.co/BZmifQ1pqL

How to Run Claude Code with Docker: Local Models, MCP Servers, and Secure Sandboxes
Docker now enables developers to run Claude Code locally, connect it to external tools, and sandbox its actions. Using Docker Model Runner, Claude Code accesses an Anthropic‑compatible API, giving full control over data, infrastructure, and spending. The Docker MCP Toolkit...

Skip Lengthy Guides—Use Agentic CLI for GKE Fixes
I don't want to read a giant troubleshooting guide, even a great one like this for GKE clusters. https://t.co/13E0PvzrMI Feed this as context into your agentic CLI (or use our @googlecloud Docs MCP) and send your agent down the right path faster.

What to Expect From Kubernetes 1.36
Kubernetes 1.36 is slated for release on 22 April 2026, continuing the CNCF’s three‑times‑a‑year cadence. The update emphasizes security, bolstering Linux user namespaces to improve container isolation and refining the WatchCache for faster API queries. It also retires the Ingress‑nginx controller, positioning...

NanoClaw and Docker Partner to Make Sandboxes the Safest Way for Enterprises to Deploy AI Agents
NanoClaw has partnered with Docker to run its open‑source AI agent platform inside Docker Sandboxes, providing enterprise‑grade isolation for autonomous agents. The integration leverages MicroVM‑based sandboxes, allowing agents to install packages, modify files, and access external systems without exposing the...

Taming CRM Releases in a Regulated FinTech Environment
EXANTE replaced its manual Saturday‑only CRM deployments with a fully automated pipeline that now serves over 30 services across multiple jurisdictions. The new flow triggers on a Git tag, builds images, creates Jira tickets, posts to Slack, and uses Flux...

What We Learned After Finding 7 Forgotten Jobs Running for 5 Years
Buffer discovered seven background jobs running on Amazon SQS for up to five years despite providing no value. A recent repository consolidation allowed engineers to map queues and identify the orphaned workers, leading to their incremental removal. The cleanup eliminated...

KubeCon + CloudNativeCon Europe 2026 Co-Located Event Deep Dive: Observability Day
Observability Day, a co-located event at KubeCon + CloudNativeCon Europe 2026, brings together CNCF observability project maintainers and practitioners. The program expands beyond traditional monitoring, highlighting AI-driven trace analysis, cost‑efficiency strategies, and large‑scale telemetry engineering. Featuring two parallel tracks, the...