
Stanford MS&E435 Economics of the AI Supercycle | Spring 2026 | Enterprise Internal Knowledge
Yash Bottel, founder and CEO of Applied Compute and an OpenAI alum, described his rapid path from Stanford to OpenAI research and then to founding a startup that helps enterprises build specialized AI models. Drawing on work in post-training, evals, and agentic coding (e.g., CodeEx and Long Horizon Tasks), he argued that frontier reasoning models are powerful but lack domain-specific business knowledge. Applied Compute’s approach is to combine these frontier techniques with proprietary enterprise data to create tailored models that improve real-world workflows. The talk also placed recent AI advances in historical context—highlighting how scale in compute and data since AlexNet has driven dramatic gains in capabilities.

Infrastructure & Ops Superstream Highlights
Speakers warned that as AI agents proliferate, platform engineers must prioritize security, governance and observability over the flashy agent logic. They urged firms to build the “boring” infrastructure first—encryption, cross-instance coordination, telemetry, and strict isolation—because agents can interact unpredictably with...

Why Most Agentic AI Projects Never Leave the Pilot Phase - Temporal Episode 2
The Temporal panel dissected why most agentic AI projects stall at the pilot stage, emphasizing that the leap from flashy demos to production hinges on durable execution. While large language models now handle complex, multi‑turn tasks, the surrounding infrastructure—state persistence,...
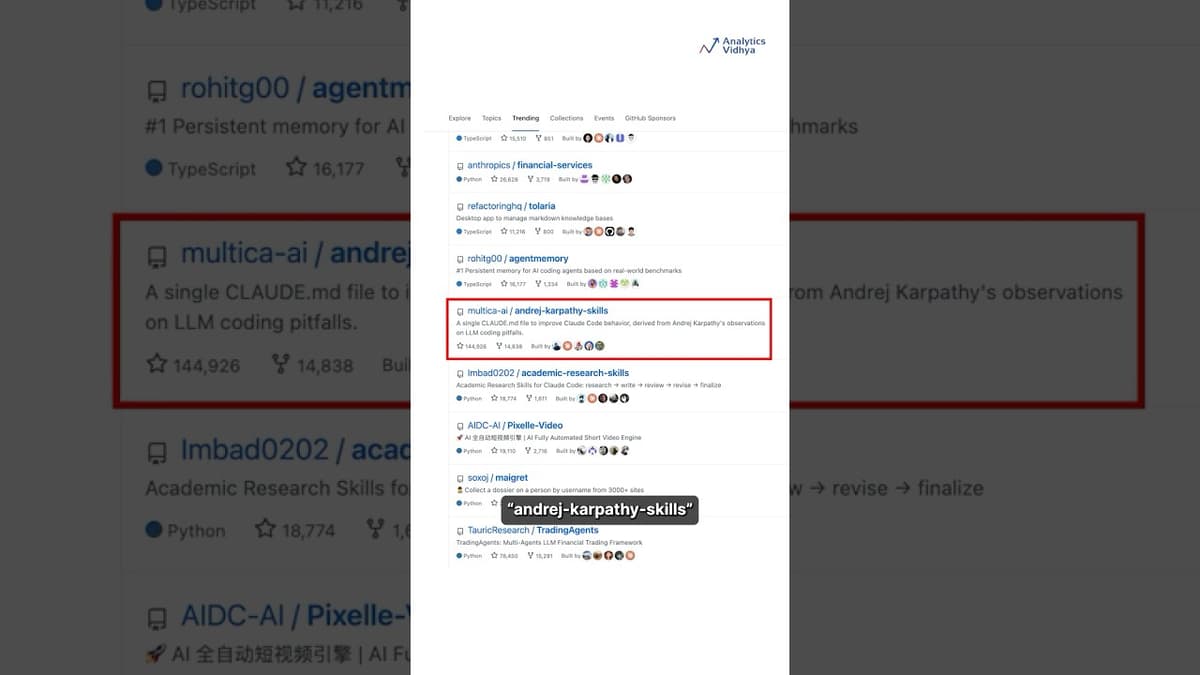
Andrej Karpathy's AI Coding Setup Just Went Viral"
Andrej Karpathy, former OpenAI founding member and ex‑Tesla AI director, has sparked a wave of interest with his new AI‑coding workflow, now hosted in a public GitHub repository called “andrej‑karpathy‑skills.” The repo packages a system‑prompt strategy that treats large‑language‑model assistants...
Backlash for AI Video of Holocaust Survivor | DW News
Germany’s Social Democrats sparked backlash after their parliamentary group published an AI-generated video of Jeanette Wolf — widely described as the only female Holocaust survivor who became a member of the Bundestag — that put words in her mouth and...

SecTor 2025 | Exploiting Multi Agent Systems
The SecTor 2025 talk focused on the emerging security challenges of multi‑agent AI systems, especially the ways attackers can exploit prompt injection and tool misuse. The speaker, a ServiceNow red‑team veteran, outlined how agents orchestrate tasks, interact with tools, and...

Master These 6 AI Skills Before It's Too Late
The presenter argues that AI usage has evolved well beyond simple chat-style prompts and outlines six essential AI skills for 2026, including advanced prompt engineering, using extended “thinking” models and context connectors, deep research with tools like Notebook LM, building...

AI Dev 26 X SF | Andi Partovi: Why Every Agent Needs a Simulation Sandbox
Various AI CTO Andi Partovi argued that builders of autonomous, action-based agents must use realistic simulation sandboxes to test and harden systems before production. He explained agents are nondeterministic, interactive, and operate in partially observable environments, so traditional static test...

AI Dev 26 X SF | João Moura: Building Recurring, Governed, and Embedded Enterprise Workflows
CrewAI CEO João Moura argues that modern enterprises can experiment with AI but struggle to operationalize it at scale. He describes a shift from ad‑hoc automations to recurring, governed workflows embedded in core processes. Drawing on real production deployments, he...

What “AI-Bookable” Actually Means for Hotels & STRs
The episode breaks down Google’s new Universal Commercial Protocol (UCP) and its promise to make hotels and short‑term rentals directly bookable through AI assistants. By embedding a catalog of inventory into Google’s surface, guests can complete a reservation from an...
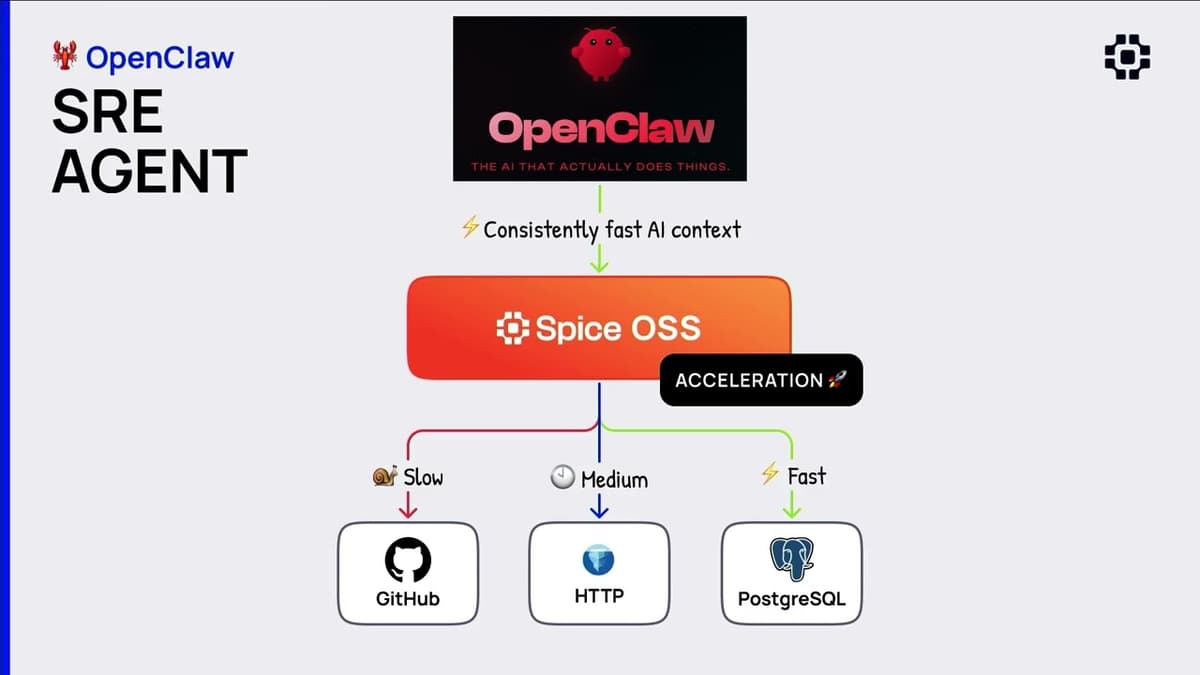
AI Dev 26 X SF | Luke Kim: The Agent Data Stack—Why Every AI Agent Needs Its Own Data Stack
Luke Kim, founder and CEO of Spice AI, warned that the modern centralized data stack built for analytics cannot meet the demands of the emerging AI agent era, where many persistent agents need fast, real-time access to diverse enterprise data....

Tech Podcast | GTC Review: NemoClaw, Groq, and SpectrumX | AI With Sally
The AI With Sally podcast recapped NVIDIA’s GTC highlights, focusing on the rapid rollout of Grok’s V3 AI accelerator, the debut of Spectrum X co‑acked optical networking, the emergence of the secure Nemo Claw wrapper for OpenClaw agents, and the unveiling of the Vera Rubin...

The Next Phase of Artificial Intelligence
The panel discussed the "next phase" of artificial intelligence, emphasizing a shift from language‑centric models to physical AI that can understand and act in the real world. Speakers highlighted world‑model research, multimodal and multiscale architectures, and the growing need for...

Automating Human-Centric NetOps Is Finally Achievable
The episode of Total Network Operations introduces Kent CEO Avi Freriedman discussing how network observability has evolved and why automating the human aspects of NetOps is finally feasible. Freriedman explains Statseeker’s 60‑second full‑fidelity polling eliminates sampling gaps, giving operators real‑time, historical...

Chip Design From the Bottom up – Reiner Pope
Reiner Pope, CEO of chip startup MatX and former Google TPU architect, delivered a blackboard lecture that builds chip understanding from basic logic gates to complex accelerators. He walks through constructing a multiply‑accumulate unit, the role of multiplexers, and the...

Singapore Police Force Rolls Out AI and Autonomous Tech to Boost Operations
Singapore’s Police Force is introducing a suite of AI‑driven and autonomous technologies to augment its operational capabilities. The rollout includes eight aerial drones for hard‑to‑reach surveillance, an unmanned boat capable of self‑navigation and docking, and service robots already patrolling Changi...

The Human Edge in AI Sales
A sales leader argues that when leading AI vendors deliver comparable technology on short timelines, human relationships and trust become the decisive differentiator. He illustrates this with an anecdote about a rep who quietly taught a client's child guitar during...

Jon Kelly in Conversation with Philipp Schindler
In a candid conversation with Google’s Philipp Schindler, the scale of AI spending across the tech sector was highlighted, with Google committing roughly $180‑190 billion this year—about double the prior year’s outlay. Schindler framed this surge as a full‑stack strategy, integrating...

AWS Certified AI Practitioner (AIF-C01) Exam Questions 2026 | 40 Mock Questions With Explanations
The video walks through AWS AI practitioner exam-style scenarios, recommending fully managed services and best-practice ML techniques. For healthcare document processing, it endorses Amazon Textract for structured extraction paired with Amazon Comprehend for PII detection and redaction, citing HIPAA-eligible, no-training-required...

The AI Opportunity Window Is Wide Open Right Now
Speakers argue that the current AI moment presents an unusually broad and accessible window of opportunity, where even modest familiarity can deliver outsized advantages. The barrier to meaningful adoption is low, so professionals who act now—whether to streamline workflows or...

AI DevOps Projects Course | Zero to Hero Series with 5 FREE Projects
The video announces a new YouTube series – “AI DevOps Projects” – offering five free, hands‑on projects that illustrate how artificial intelligence can be embedded into everyday DevOps and cloud workflows. Abishek frames the series as a response to the...
Anthropic Is Raising Prices And Pissing People Off
Anthropic announced a 50% increase in weekly Claude Code limits through July 13, but simultaneously unveiled a new subscription structure that will charge users at the higher API rate once monthly credits are exhausted. Under the revised plan, each tier provides...

AI’s Transformative Impact on Financial Services | Snowdrop Solutions, Google and Piraeus Bank
The panel at Money2020 highlighted how AI, powered by Google’s Gemini model and Google Maps, is reshaping financial services. Snowdrop Solutions, a long‑time Google partner, demonstrated its collaboration with Piraeus Bank to embed generative AI directly into banking apps. Snowdrop uses...

Is Wikipedia Ruining AI Accuracy? 🧐 #ai #tips
Wikipedia and Google’s knowledge panels are major sources for AI training data and outputs, so inaccuracies on those pages propagate widely across AI systems. Because large language models train on web snapshots, errors that existed months ago can continue to...

AI as Social Technology: Astor Lecture by Professor Henry Farrell
Professor Henry Farrell, a political scientist at Johns Hopkins, delivered the Astor Lecture titled “AI as Social Technology.” He argued that large‑language models and related AI systems should be understood not merely as intelligent agents but as a new form...

How CJ Hutsenpiller Crushes AI
The Insurance Guys podcast episode spotlights how AI is reshaping insurance agency operations and marketing. Host Scott Howell and guest CJ Huntpillar discuss the surge in advertiser interest, the shift from event‑based promotion to podcast sponsorships, and the rapid evolution...

Cisco Builds AI Defense with Codex
Cisco announced that its AI Defense suite is now being written entirely by OpenAI's Codex, turning the large‑language model into a co‑developer for its security products. By leveraging Codex, Cisco reduced feature delivery from multiple quarters to a matter of weeks....

I Built the Same App With Claude Code and Codex
A developer ran a head-to-head build of a real-time collaborative Markdown editor using Claude Code (Opus 4.7) and Codex (GPT‑5.5), testing eight staged prompts from scaffolding through real‑time sync, cursor presence, and persistence. Claude produced a working scaffold faster (about...

Spotlight: Arkeus
The video spotlights Archus at Soft Week 2026, unveiling AI‑driven hyperspectral sensors that act as the eyes and brain of autonomous platforms. Pat McCann and Simon Olsen explain how the Warden and HSOR systems process raw data on the edge,...

AI Agents Expand Enterprise Security Attack Surface
The conversation with Nomi Security CEO Emanuel Salmon centers on how AI agents are reshaping the enterprise attack surface. While traditional IT, cloud, and IoT have already expanded threat vectors, AI introduces a multi‑layered frontier that spans infrastructure, identity, and...

Your AI App Should NOT Depend on One Model
The video introduces Zapier’s MCP (Model Connectivity Platform) server, a unified gateway that lets AI applications access over 8,000 third‑party tools through a single integration point. By linking a Claude‑based app to Zapier’s MCP client, developers can manage credentials and...
The Wrong Metric Most Leaders Are Using for AI Adoption #short
The video warns that many CTOs and engineering heads measure AI adoption by the percentage of employees who use AI tools, rather than by tangible business outcomes. The speaker argues that success should be defined around concrete process improvements—identifying a task,...

SM Lee on ‘Embracing’ AI as the Chinese, US-China Relations
SM Lee urged countries to “embrace” AI while acknowledging the technology’s social and geopolitical challenges, arguing that thoughtful adoption and preparation can avoid a sudden jobs crisis. He said US-China relations have seen sharp short-term fluctuations but a long-term shift...

196. AI Meets Programmatic: How Media Buyers Can Optimize with AI
The session titled “AI Meets Programmatic” was a live workshop where Ellen Parker and Asetu walked media buyers through applying artificial‑intelligence tools to programmatic campaign optimization. They demonstrated how a simple Excel sheet can be fed into an AI engine—currently MediaMath’s...

Microsoft Copilot Is A Disaster
Microsoft has poured an estimated $200 billion into its AI Copilot suite, yet usage remains under 3% of Windows 11 devices. A former Microsoft vice‑president aired criticism on Twitter, igniting a rapid online debate. The video dissects the low adoption figures, recent...

How to Build & Launch REAL Web Apps (Google AI + Firebase)
The video walks viewers through building a production‑grade web application using Google AI Studio paired with Firebase. It demonstrates how AI Studio can generate a complete front‑end and back‑end from a structured prompt, eliminating the need to write code manually....

Inside Bob Jennings’ Vision for TrustEngine and Mortgage Coach
Bob Jennings, CEO of Trust Engine, used a 10‑minute interview to outline his vision for Mortgage Coach, the company’s flagship platform that helps loan officers present mortgage options. He reflected on his first 90 days, confirming that Mortgage Coach has...

Sobel Edge Detector Introduction | Image Processing Basics || Verilog Project Development Series ||
The video is an introductory lesson for a Verilog project implementing the Sobel edge detector, beginning with prerequisites on image fundamentals. It explains grayscale versus RGB color images, pixel and subpixel structure, 8-bit channel intensity (0–255), and additive color mixing....

Viewpoint Friday: AI Boom, Rising Costs and Singapore’s Multi-Speed Economy
Singapore’s economy is becoming distinctly multi-speed: AI-driven demand for semiconductors and tech exports is lifting trade and certain manufacturing pockets, even as rising energy and commodity costs squeeze services, F&B and everyday goods. Businesses are responding with cost-passing, efficiency drives...

What Is FastAPI & Why It's Perfect for AI Backends
The video introduces FastAPI as the modern Python framework tailored for generative‑AI backends, explaining its role as the thin layer that exposes, serves, and hardens AI logic for production use. It highlights FastAPI’s foundation on Starlette for routing and async...

The Dawn of AI Warfare: A Conversation with Katrina Manson
The CSIS interview with Bloomberg reporter Katrina Manson centers on her new book, *Project Maven*, which chronicles the U.S. military’s push to embed artificial intelligence into combat targeting. Manson traces the program’s origins—from a tactical tool for sorting drone footage—to...

Why Teens Are Turning to AI for Mental Health | Caroline Figueroa
The Health Affairs episode spotlights a growing crisis: teens are turning to AI chatbots for mental‑health support despite the tools not being designed for clinical use. Dr. Caroline Figueroa, a Stanford psychiatrist, cites tragic cases where AI interactions preceded suicides,...

Why Is Trump Pulling the Plug on His AI Order? | DW News
President Trump abruptly withdrew plans to sign an executive order on artificial intelligence hours before a scheduled White House event, saying aspects of the proposal could blunt the U.S. lead in AI. The draft order would have required tech firms...

DeepSeek’s New AI Is A Game Changer
The video spotlights DeepSeek’s new AI architecture that replaces traditional dense visual processing with a "pointing" paradigm, allowing the system to reference specific image regions while reasoning. By treating visual primitives as tokens, the model slashes visual token consumption by...

"A.I. and Our Economic Future," Professor Chad Jones
In a wide-ranging lecture, economist Chad Jones outlined two extreme futures for AI: a Silicon Valley “explosive growth” scenario in which AI automates software, accelerates research, and — when paired with robotics — automates physical tasks, producing runaway productivity gains;...
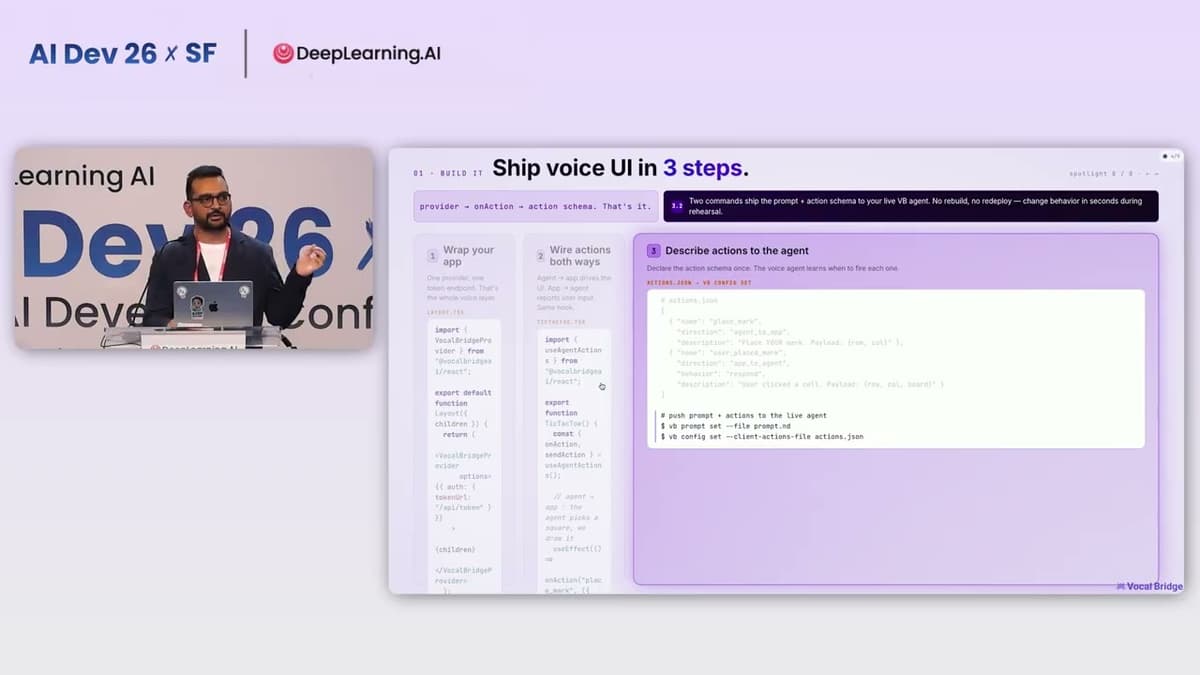
AI Dev 26 X SF | Ashwyn Sharma: Every App Needs a Voice UI. Here's How to Build It
Ashwin Sharma, CEO of Vocal Bridge, unveiled a platform that turns any application or AI agent into a voice‑first experience. The company positions itself as a one‑stop, fully managed solution, offering three distinct integration surfaces: embedding voice directly into existing...
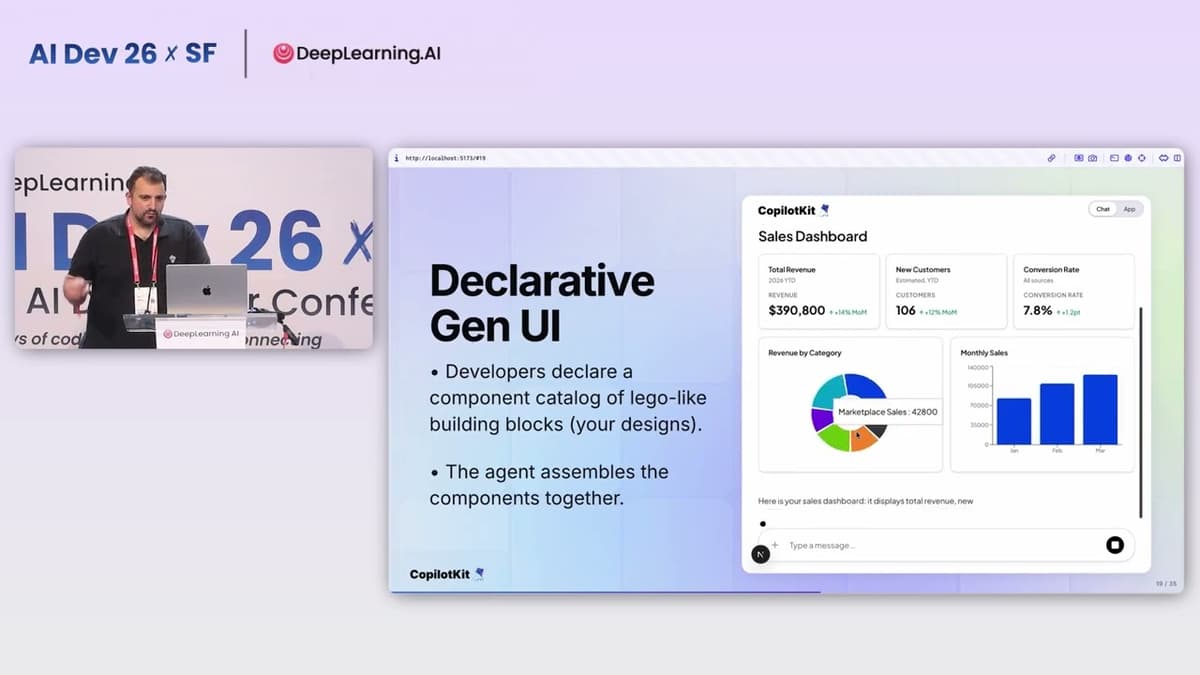
AI Dev 26 X SF | Atai Barkai: Fullstack Agents & Generative UI with AG UI
Atai Barkai of Copagit outlined the company’s developer infrastructure for user-interactive agents and introduced the Agent-User Interaction (AG UI/AGI) protocol, which standardizes how agent backends connect to user-facing interfaces. He argued that agentic systems break the traditional request-response web model—requiring...

AI Dev 26 X SF | Idan Raman: The Identity Crisis of Browser Agents
Idan Raman, CEO of Ankor, laid out what he calls an "identity crisis" for browser-based AI agents, arguing that retrofitting 20 years of human authentication for autonomous agents uncovers deep, unexpected complexity. He described common but insecure customer approaches—embedding or...
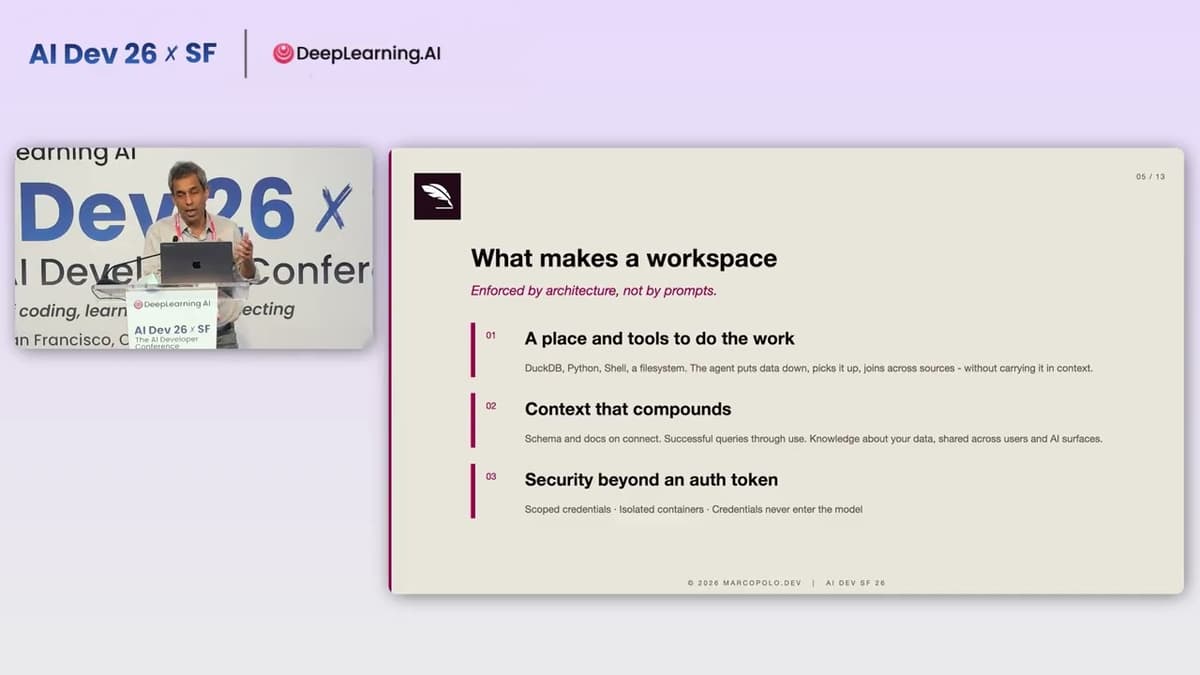
AI Dev 26 X SF | Aman Singla & Aseem Chandra: MarcoPolo, A Workspace for AI to Work with Your...
The video introduces Marco Polo, a middleware platform that provides a dedicated workspace where agentic AI models—such as Claude, ChatGPT, or custom agents—can safely access and manipulate enterprise data across dozens of systems. By running in a secure Kubernetes container,...
AI Dev 26 X SF | Barun Singh & Kennith Jackson; The Hidden Cost of AI Velocity and AI Agents
The panel, hosted by Endela’s SVP of AI Solutions and its CPTO, examined the hidden costs of AI velocity and the hype around autonomous AI agents. They argued that while AI coding assistants like Copilot boost speed in isolated tasks,...