
Hermes Agent Tutorial for Beginners - Step by Step
In this step-by-step tutorial, Matt walks viewers through deploying a Hermes Agent—an open-source, self-hosted AI assistant from Nous Research—on a VPS (using Hostinger) and connecting it to Telegram for mobile access. He explains Hermes’ key features: always-on background operation, persistent personalized memory, and reusable skill creation, and demonstrates choosing an appropriate VPS plan (Hostinger KVM 2), account setup, and accessing the server terminal. The video also covers scheduling automated jobs, security considerations, cost expectations, and an option to run Hermes locally instead of on a VPS. Matt notes Hermes can import OpenClaw setups and that Hostinger’s preconfigured deployment and discount simplify installation.

Stanford CS336 Language Modeling From Scratch | Spring 2026 | Lecture 16: Post-Training - RLVR
The lecture introduces Reinforcement Learning from Verifiable Rewards (RLVR) as the next frontier beyond instruction tuning and RLHF, focusing on tasks such as mathematics and code where outcomes can be objectively verified. It highlights recent OpenAI announcements that a thinking...

05/22/26: ChatGPT Confesses to Crime It Didn't Commit, Smart Glasses in Courtrooms, and More
Legal Tech Week’s May 22 episode opened with a round‑table of hosts discussing the latest buzz in legal technology. The conversation quickly turned to ALM’s recent rebrand to the newly minted "Centellic" umbrella, a move critics say obscures the company’s legacy...

Inside the 2026 AI Index Report
The video walks through the ninth edition of the AI Index, highlighting its purpose to provide a data‑driven snapshot of AI’s trajectory across nine dimensions, from technical progress to economic and societal impact. The report shows AI spreading at unprecedented speed—88 %...
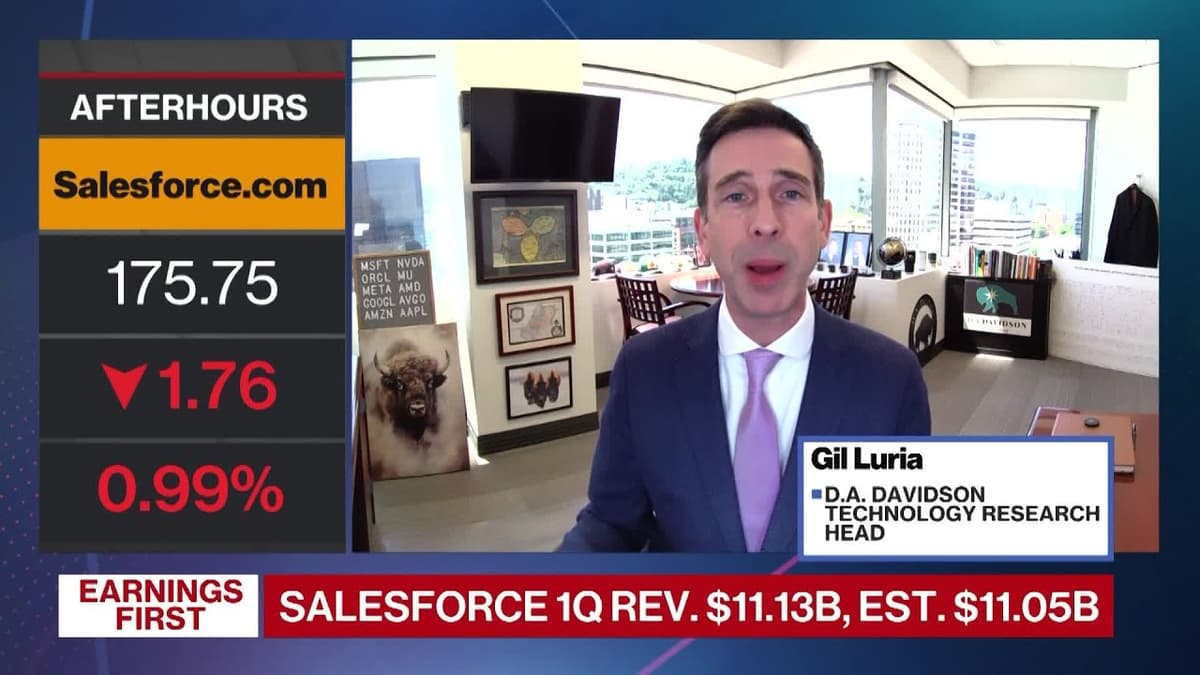
Salesforce Taking Longer Than Expected to Shift to AI, Analyst Luria Says
Analyst Gail Luria said Salesforce’s pivot to AI and its 360-degree ‘Agent’ vision is taking longer to drive revenue than investors hoped, with disappointing near-term guidance implying organic growth of roughly 6–8% next quarter versus a longer-term double-digit target. The...

AI Safety Ignores Consciousness. That's a Problem.
AI safety debates typically focus on observable behavior rather than internal states, but recent research suggests consciousness may be inseparable from advanced intelligence and could already exist in rudimentary form in large language models. The video contrasts a Kantian view...

Jason Reynolds on What AI Is Quietly Stealing From The Next Generation
Author and educator Jason Reynolds warns that AI is quietly eroding not just skills but young people’s fortitude and capacity to cope when technology fails. He argues that overreliance on AI-generated instruction or conveniences—illustrated by scenarios like drivers who can’t...

How AI Is Changing the Way Government IT Leaders Hire
Government IT hiring officials report a surge of AI‑crafted resumes that look flawless, prompting a shift in screening methods. Recruiters say the polish masks gaps in experience, so they are tightening evaluation criteria. To counteract AI‑assisted applications, agencies are leaning on...

Commiserating About AI with Ned and Kyler
The episode centers on Kyler Middleton and Ned Bellavance’s hands‑on experiments with generative AI in a corporate DevOps setting. They describe building a secure, internal ChatGPT‑style assistant called Vera, which has already fielded roughly 32,000 employee queries and integrates with...

The AI Questions Atlassian and Canva Can No Longer Ignore
Atlassian and Canva, Australia’s two flagship tech firms, are confronting the same existential question: how will generative AI reshape their business models? The Australian Financial Review podcast highlighted investor anxiety that AI‑driven “SaaS apocalypse” could undercut Atlassian’s subscription revenue, while...

Lecture 3.0.6: Risk Scores Charlson, Elixhauser, GBM, RNN, TabNet Models, REGULARISED REGRESSION
Lecture 3.0.6 of the Masters in Health Data Science program compares classic clinical risk scores—Charlson Comorbidity Index, Elixhauser Index, and NEWS2—with modern machine‑learning and deep‑learning models such as XGBoost, LightGBM, TabNet, RNN/LSTM. It walks through model selection, regularisation techniques, evaluation...

Human Edge of AI: Olaf J. Groth, PhD
In a recent lecture titled “Human Edge of AI,” Dr. Olaf J. Groth emphasizes that AI initiatives must be justified by measurable return on investment for both organizations and individual contributors. He argues that ROI is not a simple calculation of...

Human Edge of AI: Assistant Professor Solène Delecourt
Assistant Professor Solène Delecourt of Berkeley Haas warns that generative AI tools, increasingly used by MBA students for negotiation prep, carry hidden biases. Her research shows AI often infers lower experience and competence for women—particularly older women—leading to advice that recommends...

Google Just Broke SEO. Here’s What Replaces It. | Equity Podcast
The Equity Tech Branch podcast spotlights Google’s AI‑driven search overhaul announced at Google I/O, where AI‑generated answers now dominate the SERP. Brands suddenly find their traditional SEO tactics obsolete as conversational agents dictate visibility, prompting a need for “agent‑ready” websites. Matt...

DOD Wants Nearly $30B for a New AI Arsenal; Lawmakers Call for SBA to Be More Transparent on AI
The Department of Defense has requested nearly $30 billion for fiscal 2027 to build an “AI Arsenal” of next‑generation supercomputers and modernize its secure data‑center infrastructure. The budget aims to centralize and scale high‑performance computing across the joint force, enabling AI‑driven...
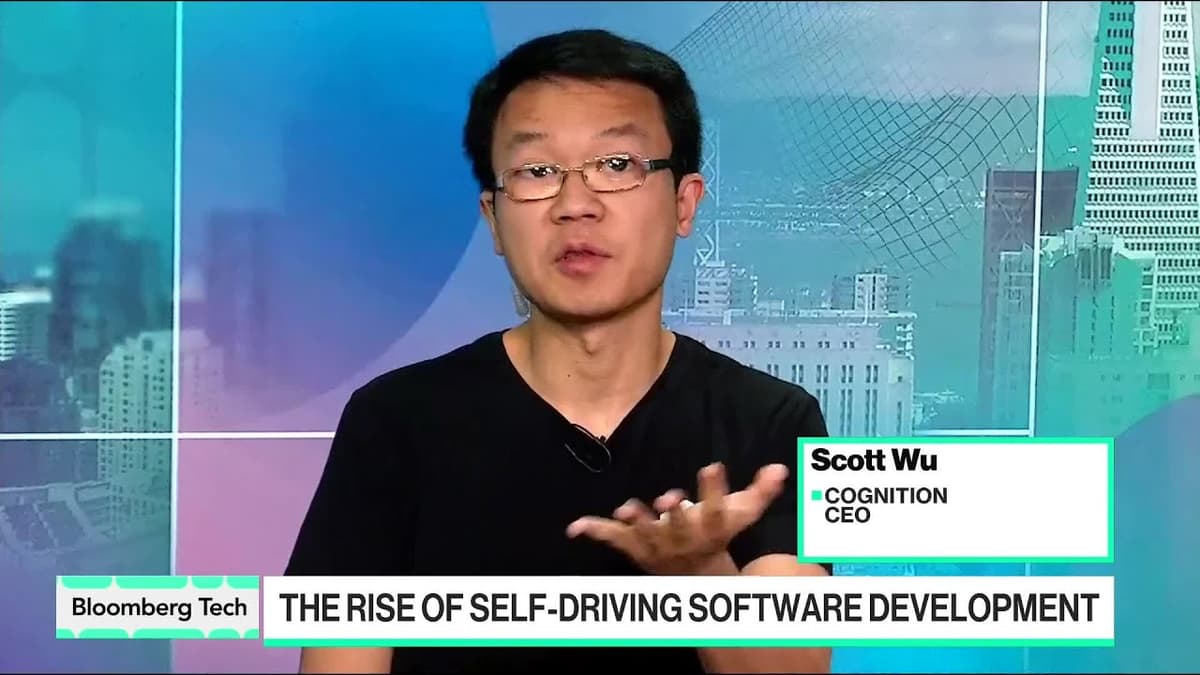
AI Startup Cognition Raises $1 Billion at $26 Billion Value
Cognition announced a $1 billion financing round that lifts its valuation to $26 billion, marking one of the largest AI‑focused raises this year. CEO Scott Bostick highlighted the company’s rapid growth, noting a jump from a few‑million revenue run‑rate in early 2024...

AI and the Future of Customer Success with Bill Tabbit-Humphrey | Alteryx Inspire 2026
At Alteryx Inspire 2026, Chief Customer Officer Bill Tabet-Humphrey described his shift from technical roles into customer-facing leadership and outlined a deliberate transformation of Alteryx’s customer experience organization from reactive support to proactive, value-driven customer success. He emphasized reframing support...

Architecting Modern AI Systems
The panel discussion centered on architecting modern AI systems, using a recent mental‑health hackathon as a case study. Organizers leveraged a self‑service Kubernetes platform on BuzzHPC to evaluate over a thousand team submissions, enabling rapid scoring, leaderboards, and a surprise...

The Black Box Problem #Explainer #StanfordGSB #AI
The video explains the ‘black‑box problem’—the opacity of modern AI models that can process vast amounts of text and data but offer little insight into how they reach conclusions. While AI’s computational power enables connections humans cannot make alone, the hidden...

Should You Still Learn to Code in the Age of AI?
The video argues that learning to code remains valuable despite AI’s growing ability to generate software. Understanding computer science gives people a practical intuition for how digital systems are built, how they can fail, and what biases or assumptions they...

3 AI Workflows Investors Should Use for Durable Edge
Behavioral expert Fred Marshall, author of Thrive, warns that AI-driven change and constant information streams are producing a modern “future shock” of cognitive overload and uncertainty. He advises investors to counter noise by curating attention, relying on trusted sources, and...

Building a 30% Better AI: The Taste Graph Moat
Pinterest’s CTO Matt Madreal explains how the visual discovery platform has built a 30% more accurate, 90% cheaper AI stack by fine‑tuning open‑source foundations. The company leverages a custom "Pin‑CLIP" embedding layer that unifies image and text metadata, enabling semantic...

Why ChatGPT Agrees with You #shorts
The video explains why ChatGPT often appears to agree with users, emphasizing that large language models (LLMs) function as prediction machines rather than evaluators of truth. It argues that the core technology predicts the next token that best fits the...

Building Production Grade Text to SQL Application Using Oracle AI Database - Select AI
The video walks viewers through building a production‑grade text‑to‑SQL application that runs entirely inside Oracle’s next‑gen 26 AI Database. By leveraging the database’s native AI capabilities, users can type plain English questions and receive automatically generated, executed SQL results without...
This AI Agent Debugs Your Entire Data Pipeline 🤯
A demo shows how to build an AI agent that debugs data pipelines by combining relational SQL queries and vector-based RAG search inside an Oracle 26 AI database. The presenter spins up an Oracle AI container via Docker Compose, loads...

Inside YC's AI Playbook
The episode reveals how Y Combinator has transformed from a pre‑AI organization into an AI‑native one by constructing an internal agent framework that runs on a single PostgreSQL data warehouse. Founder‑partner Pete Kumman describes the evolution from a finance‑focused...

Christina Wallace on AI and Entrepreneurship
The video features Harvard professor Christina Wallace discussing how AI, especially large‑language‑model agents, is fundamentally reshaping entrepreneurship and creative work. She notes that AI agents enable two‑ or three‑person startups to perform tasks previously requiring fifteen employees, allowing founders to...
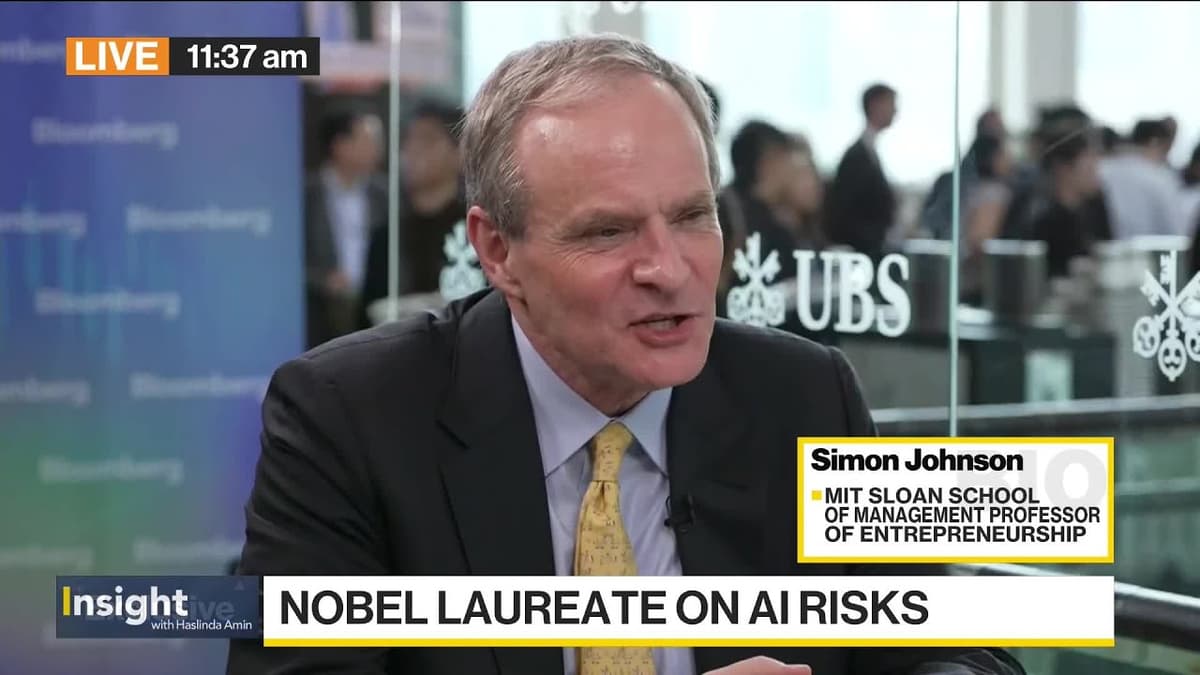
AI Automation, Job Loss Fears and Where New Work Emerges
At a recent UBS event in China, AI experts debated whether artificial intelligence will become a mass job destroyer or a catalyst for new work, drawing on their research at MIT and the forthcoming book “Power and Progress.” They argued that...

🤖 What Does It Actually Take to Reach 'Big AI' In People Analytics & HR?
The video explores how organizations transition from "little AI"—simple tools like gym‑membership style prompts—to "big AI" that fundamentally reshapes people analytics and HR. The speaker frames the journey as moving from disconnected, low‑impact applications to a strategic, enterprise‑wide AI engine...

Simplified AI Labels & Auto-Detection: What You Need to Know
YouTube announced today that it will revamp how AI‑generated content is disclosed, shifting the label from video descriptions to a more prominent on‑screen position. For long‑form videos the label will appear just below the player, while Shorts will show an overlay...

AI Engineer Salary - What to Expect: Junior to Senior
Salaries for AI engineers have surged, with average pay jumping from $156,000 to $206,000 in one year and job postings up 143% year-over-year. Entry-level AI engineers (0–2 years) in North America earn base salaries of roughly $115K–$150K and average total...

AI For Data Teams (How to Be Ready)
The video advises data teams on integrating AI coding agents—like Copilot or Claude Code—by emphasizing that success depends on strong human-led foundations rather than hands-off reliance. The presenter argues that clear instructions, formalized conventions (naming, style guides, documentation), and defined...
Here's a Fun Exercize for ChatGPT
A teacher recounts training a student to ask better questions rather than supplying answers, building investigative skills. The student then used ChatGPT to solve a problem; when prompted to critique its own prior response, the model produced a detailed rebuttal...

HOW to RUN AI MODELS Locally Using Llama Cpp and Docker
The video demonstrates how to run AI models locally using llama.cpp and Docker, outlining three official Docker image variants—light (CLI), full (everything), and server (server binary)—and advising selection based on hardware (CPU, NVIDIA CUDA, AMD ROCm, Intel options). The presenter...

I Let Codex Run for 6 Hours. Here’s What Happened.
Claravo demos OpenAI Codex’s /goal feature, showing how goal-based loops let the model run autonomously for hours by iterating, testing and self-verifying until a measurable outcome is reached. She explains when to use goals versus single-turn prompts, how to manage...

How Daily Mentor Helped Fix the Business
A business owner credits Daily Mentor with transforming operations and reversing a period of poor performance since joining before Christmas. The program provided actionable, practical guidance—helping the company prepare an Amazon launch, fix SEO, and implement a 30-60-90 day accountability...
Why Teens Turn to AI #ai #parenting #children #psychology #shorts
Teenagers often turn to AI for private, nonjudgmental support on sensitive issues their family or friends may not handle well. Common topics include first relationships, sexual orientation and gender identity, coming out, mental and sexual health, and questioning family religion....

Ying Xu | AI and the Developing Child: Myths, Evidence, and Open Questions
Ying Xu’s Stanford seminar examined how preschool‑age children engage with voice‑based artificial intelligence, arguing that this demographic warrants a child‑centered AI approach distinct from adult usage. She highlighted that young learners interact with AI primarily for companionship, play, and informal...

How the Electrical Grid Is Being Rebuilt for AI | Bloomberg Primer
The video explains that the electrical grid—the world’s largest engineered system—faces a major inflection as decades of flat demand reverse due to AI, data centers, electric vehicles and electrification of heating. Meeting forecasts that electricity use could double by 2050...

AM Best: Artificial Intelligence Appears to Be Ready, but Most Insurers Are Not
AM Best’s latest market‑wide survey reveals that artificial intelligence is no longer a futuristic concept for insurers, but its full‑scale deployment remains uneven. While 41% of respondents report active AI use in core functions and 63% have formal AI policies, only...

Zedge (NYSE American: ZDGE) on AI Integration, Cost Savings and New Revenue Streams in 2026
Zedge CEO Jonathan Reich said the mobile app publisher is doubling down on AI to expand both consumer features and B2B product offerings. The company operates a large creator ecosystem — including Zedge’s personalization marketplace, GuruShots and Emojipedia — with...

Jensen Huang: The Tough Boss of Nvidia Who Is 'Exhausted All the Time' | CNA Correspondent
In a rare 50‑minute interview, Nvidia co‑founder and CEO Jensen Huang discussed the AI boom, his personal background, and the strategic challenges facing the industry. Huang bluntly rejected the claim that artificial intelligence is already causing mass layoffs, calling the narrative...

Your Family Office Is Already Obsolete 📱
Angelo Robas warns that traditional family offices are already obsolete unless they urgently integrate AI, arguing the technology has moved from novelty to execution since ChatGPT’s 2022 debut and will rapidly transform operations. He says firms that rely on standard...

Crossmedia’s AI Is Built to Free Planners From Excel Hell
Crossmedia has introduced XMOS, an AI‑driven module operating system that ingests client briefs, first‑party data, MTA, MMM, and competitive information to generate stacked media plans. The system automates reach‑frequency curves, channel allocations, and continuously learns from campaign performance, delivering efficiency gains...
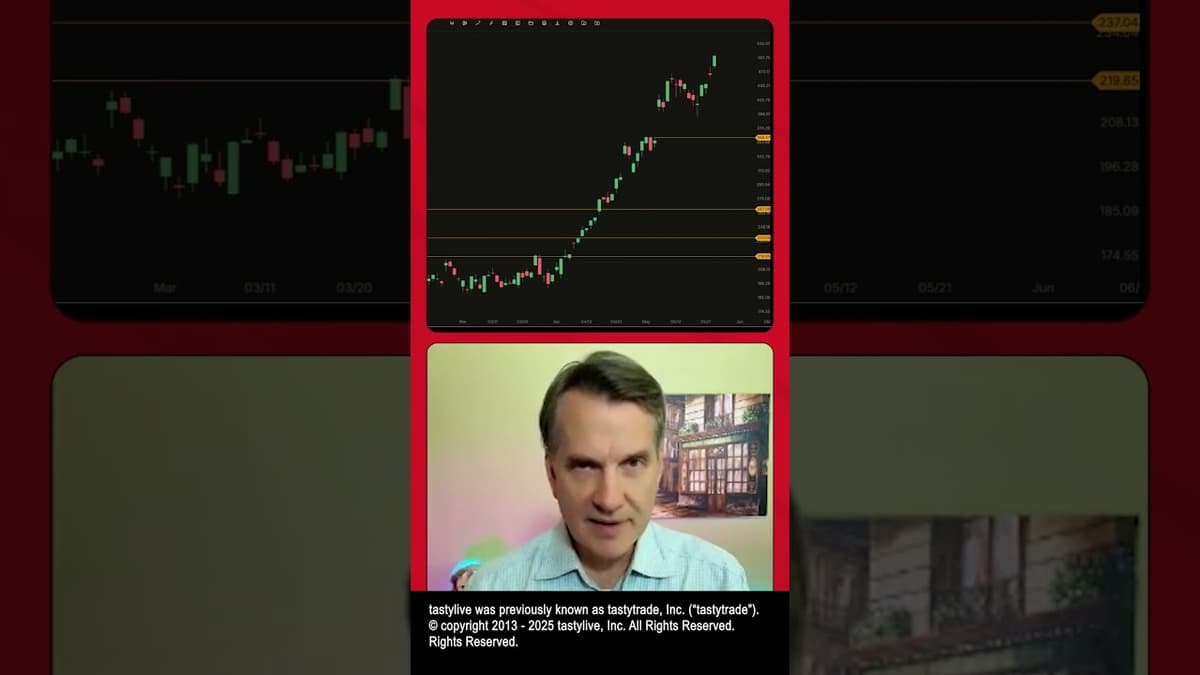
Tracking the Massive Rally in AMD and Micron
The video spotlights an extraordinary rally in semiconductor giants AMD and Micron, whose shares have rocketed several hundred percent in just a few weeks. The presenter emphasizes that these are not tiny, speculative penny stocks but massive, well‑known companies experiencing...
AI Isn’t Creating Better Hackers
The video argues that generative AI isn’t creating significantly better hackers but is enabling less experienced operators to produce and ship more exploit variants faster. In stressed environments—such as failing regimes or wartime—senior oversight is absent, so juniors rely on...

Ep46 Two AI Extinction Moments Coming for Enterprise Sales | EQ You × AI
The episode warns of two looming extinction events in enterprise sales: revenue leaders (CROs) who roll out AI tools without embedding them into daily workflows, and frontline sellers who refuse to use those tools to create customer value. The host uses...

From "Test Prep" To Real Growth: A New Way to Look at Interim Assessments
Khan Academy unveiled a new suite of interim assessments that leverage conversational AI to move beyond traditional multiple‑choice testing. The platform delivers authentic, interactive math, reading, and writing tasks while providing teachers with real‑time data and actionable next steps. AI‑driven...

How Wyebot Utilizes MCP Servers to Protect Corporate AI Data Privacy
Wyebot introduced a Managed Compute Platform (MCP) server solution that lets enterprises run large language models without exposing their proprietary data to cloud‑based AI services. The offering requires customers to supply their own API tokens and keys, while Wyebot supplies...
The Investment Ecosystem Is Evolving Fast. The Question Is Whether Your Portfolio Is Keeping Up.
The video examines how the investment ecosystem is rapidly shifting, urging investors and limited partners to rethink portfolio construction and risk management in light of AI‑driven technologies. It argues that traditional allocation models may no longer capture the value drivers...